Kafka分布式数据平台
Kafka即可作为系统集成的消息中间件和数据存储系统,提供发布订阅和数据存储能力,也可作为流数据的实时计算平台。
Kafka Cluster
Kafka集群由一个ZooKeeper服务和无数的Broker节点构成,
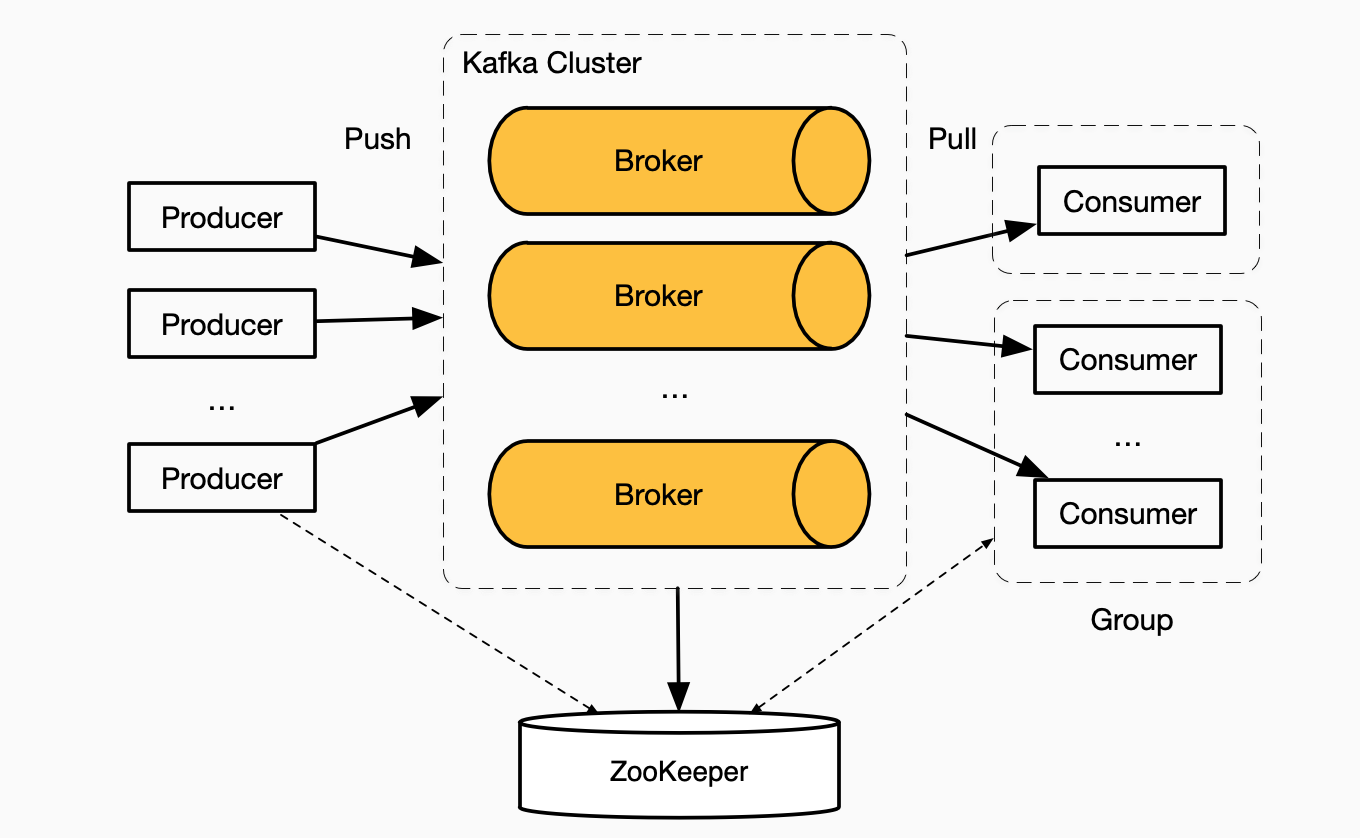
- ZooKeeper,是一个独立运行于Kafka外部的服务,它为分布式应用程序提供高性能的协调服务,包括Leader选举、分布式锁、以及集中配置等分布式系统的核心问题;
- Broker,Kafka服务节点,也是消息的存储节点。
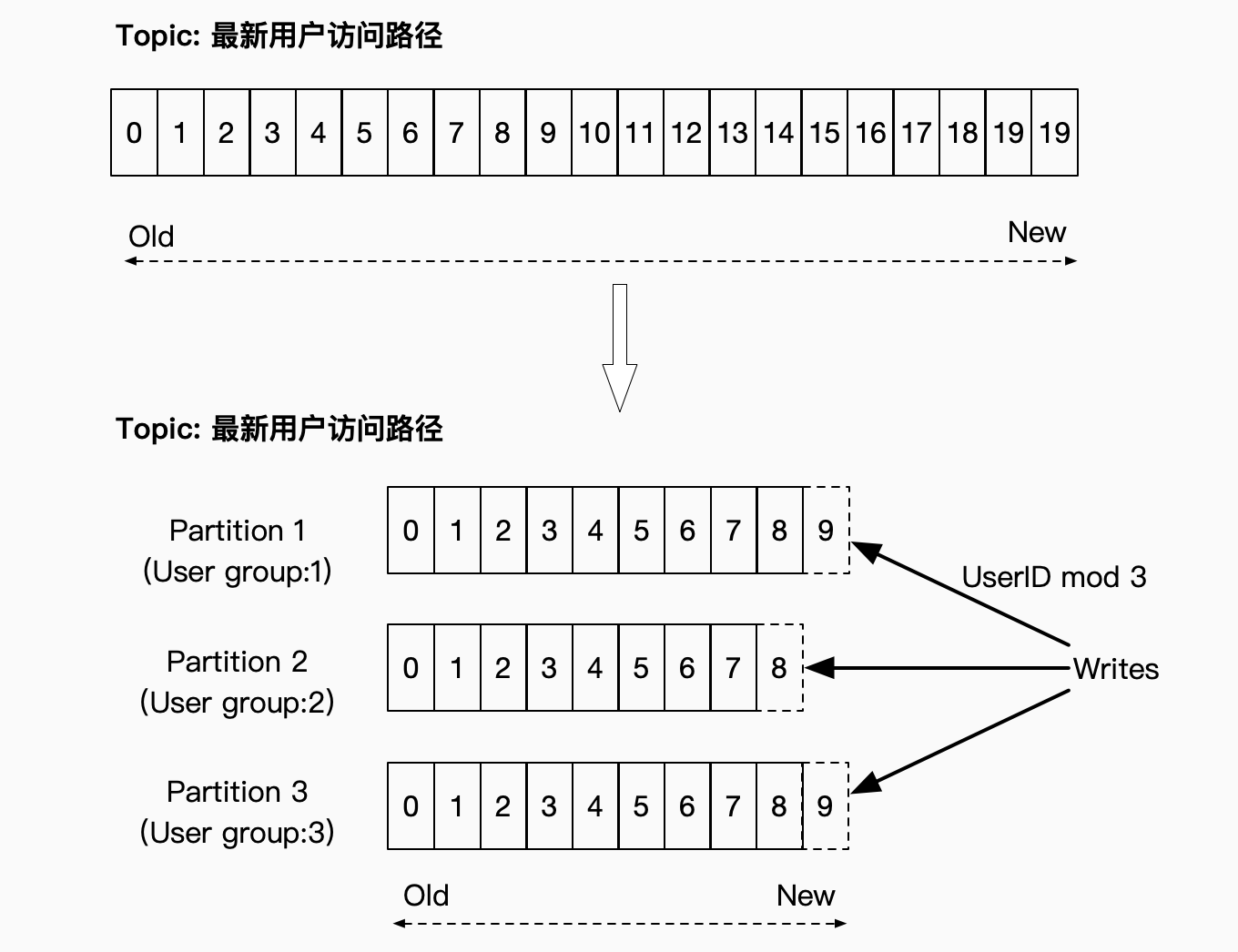
Kafka的消息数据以Topic的形式进行分类,同一个Topic的数据,物理存储上还会进行Partition(数据分片)。 同时,每个Partition是一个有序的队列。选择适当的维度进行Partition的划分,比如按UserID进行划分,保障同一个User的数据在一个有序的Partition中,最终使得Consumer在这个Partition中获得有序的消息,
Kafka用多个Broker进行数据存储,利用ZooKeeper实现了一致性的分布式存储,
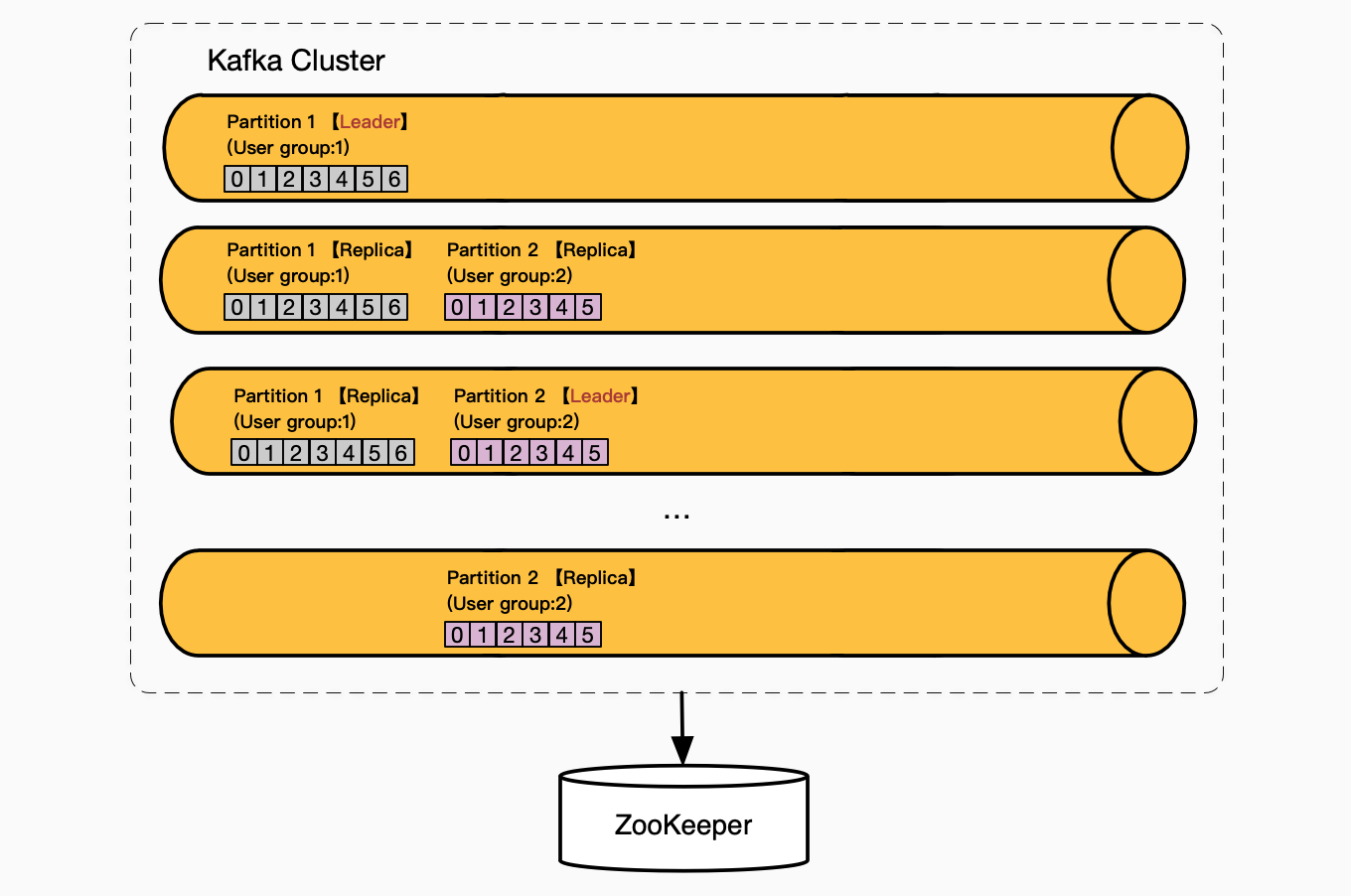
- 每一个Partition会被复制到多个Broker(节点)上,以提供容错性。这些Replica中会有一个Leader,负责读写,其他的Replica叫做Follower,被动接收复制数据;
- 如果Partition Leader失败,利用ZooKeeper,会在Followers中选举出新的Leader来进行读写,其他的Follower从新的Leader复制数据; Cluster和Partition的设计,给Kafka带来了可伸缩性(无限存储)、容错性(即使部分节点失败也不会丢失数据)、以及高性能(均匀分配)。
Kafka的参与角色
围绕Kafka Cluster,有四种参与角色:
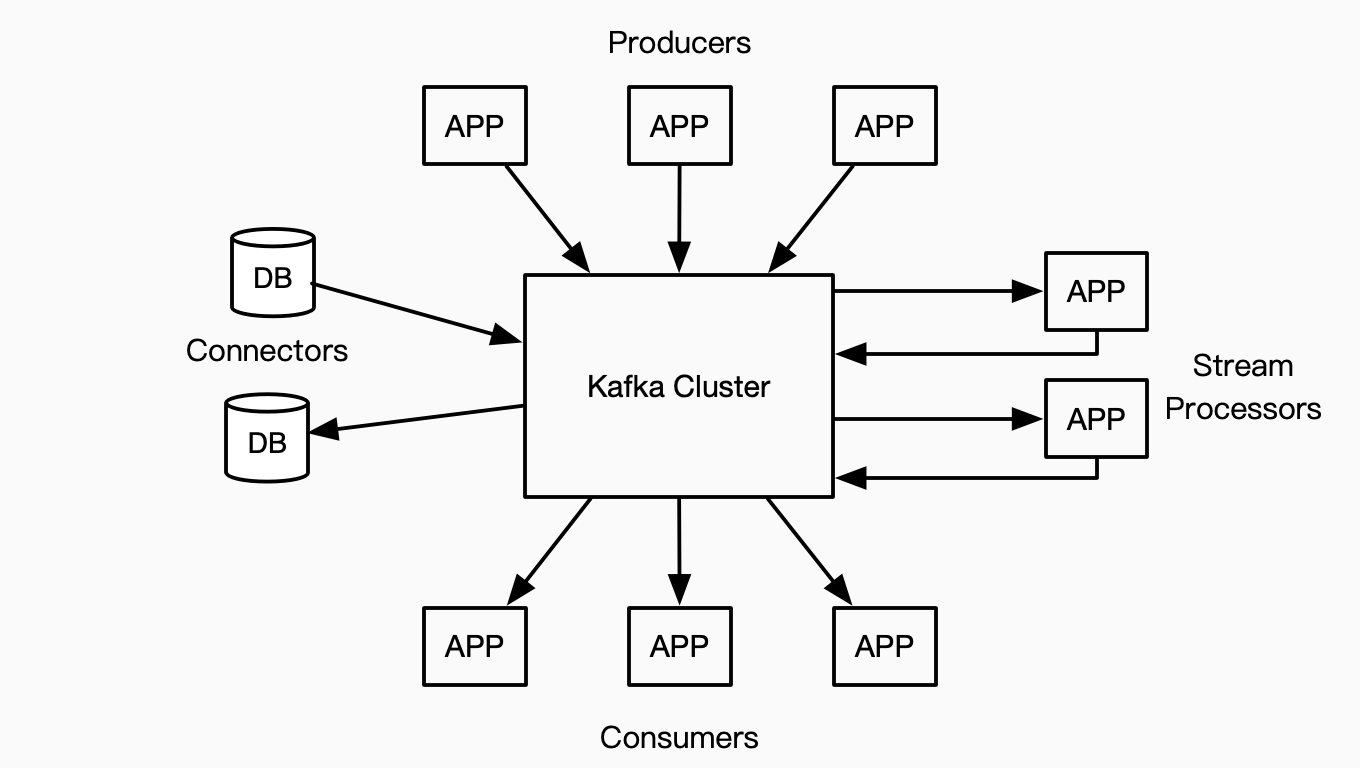
- Producer,消息发布者,发布消息到一个或多个Topic(消息分类);
- Consumer,消息订阅者,可以订阅一个或多个Topic,当Topic有消息产生时,Kafka会及时把消息推送给Consumer;
- Connector,用于从其他数据系统(如数据库)导入数据到Kafka,或者将Kafka数据导出到其他系统。这一点功能上类似Apache Flume,不同的是,Kafka Connect解决的是Kafka与其他数据系统间的传输问题,而Flume可以更加灵活适配不同的数据源和目的地;
- Stream Processor,流处理器,通过订阅一个或多个Topic,然后对产生的流数据进行处理,把处理结果再重新发布到Topic。这也就是Kafka Stream,Kafka提供的实时流计算功能。
应用场景
一、用作消息中间件
系统集成时,往往需要一个消息中间件,充当数据的通道和存储。消息中间件有两种常见的消息模型:队列模型(queue)和发布订阅模型(pubsub)。这两者有一些重要的区别,
- queue消息只能被一个consumer处理,而pubsub可以把消息广播给多个订阅者;
- queue消息可以同时被多个consumer并行处理,提升处理效能,但pubsub的每一个consumer会独自面对这个Topic订阅的所有消息;
Kafka利用了Consumer Group的概念,结合了queue和pubsub的优点。
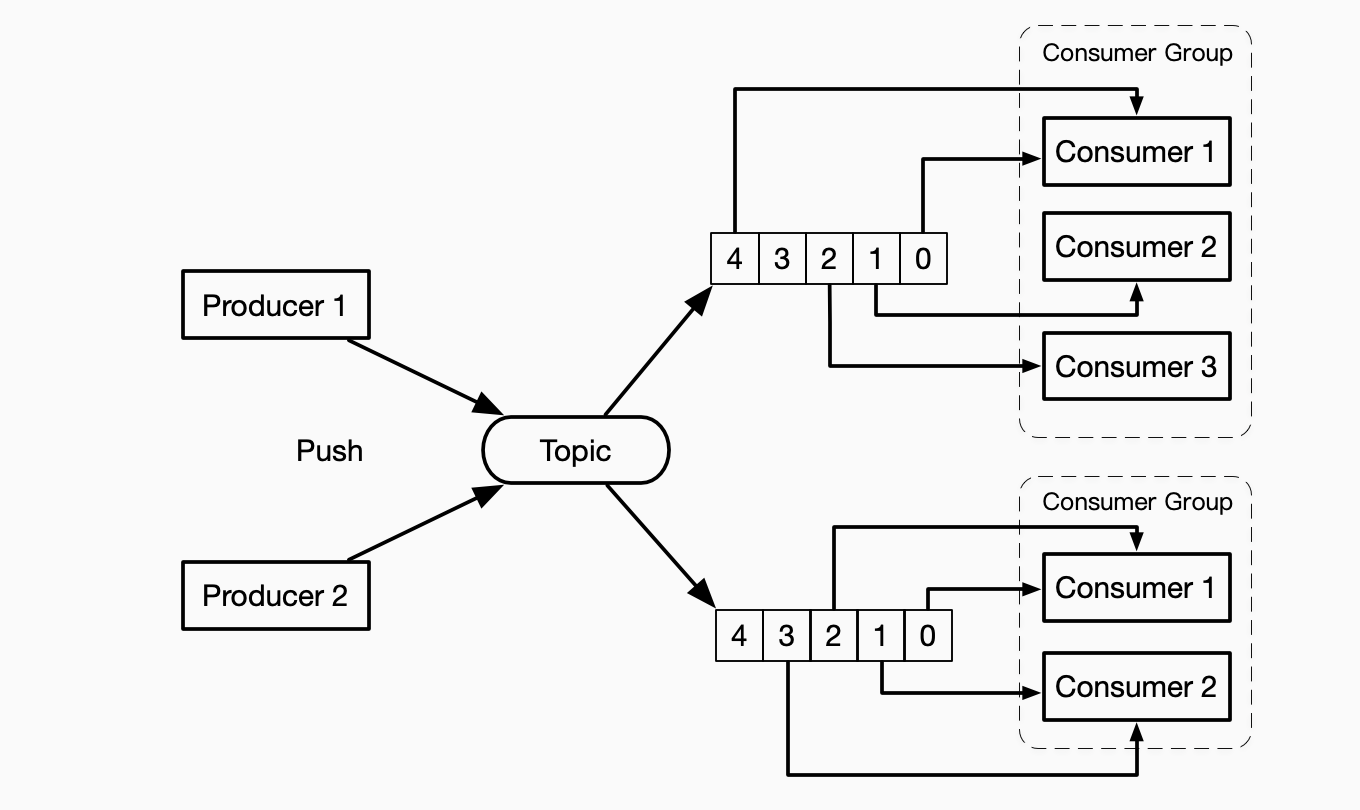
pubsub可以广播消息到多个Consumer Group,在一个Group内保证每个消息只有一个Consumer,于是可以在Group进行并行处理。
对于多个Consumer并行处理消息的场景,一般情况下是可行的。消息在Broker中进行了排序,但是异步到达多个Consumer后,并不能保证执行的先后顺序。对于消息顺序有强要求的场景,则可以利用Partition来解决,
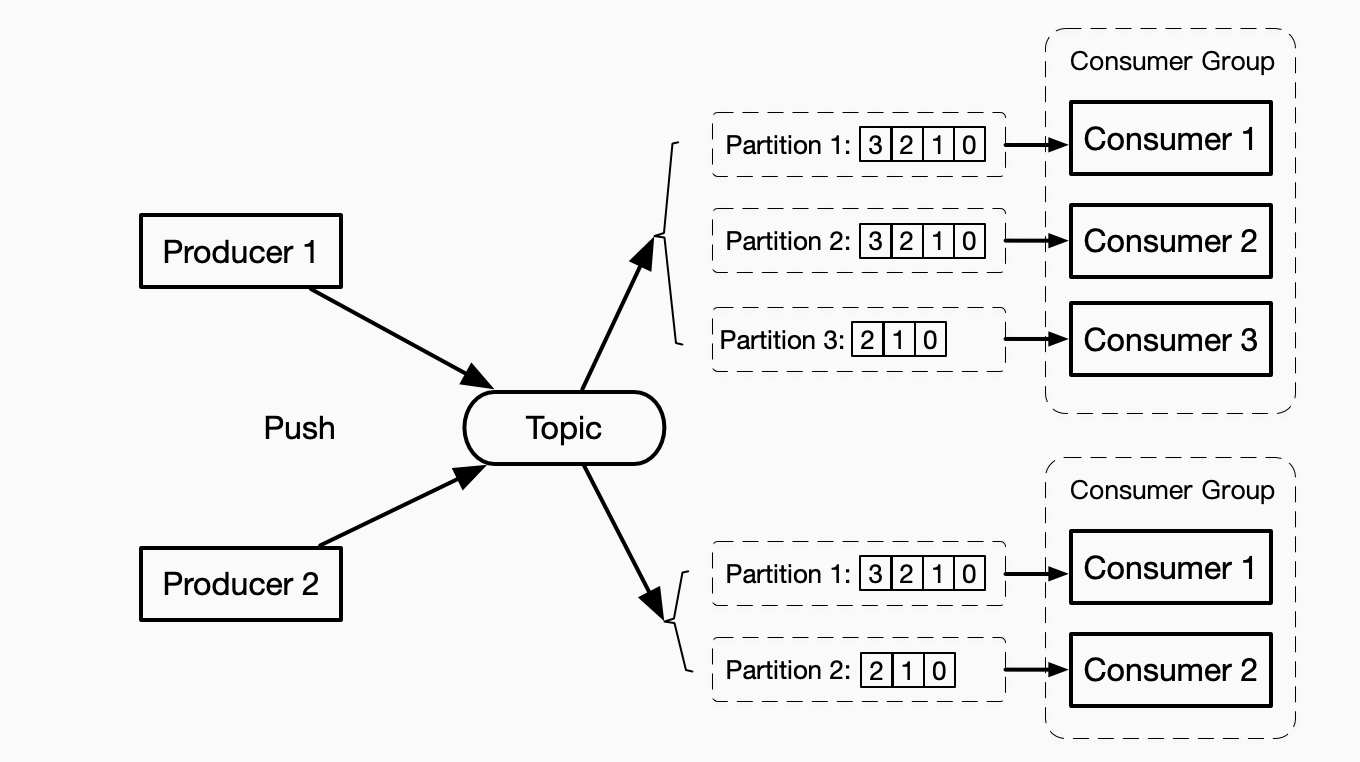
通过适当的对Partition进行规划,把一个Topic的数据切分为更小的分片,Kafka保障每一个分片中消息的有序性,每一个Consumer指定消费一个分片,完成有顺序的消息处理。
二、用作流计算
相比老牌的流计算框架(STORM、Spark Streaming和Flink),Kafka Stream是后来者,但是凭借“Simple is beautiful”的设计理念,给开发者带来了更简化但更强大的流计算。
它设计的简化主要体现在,
- 仅仅是一个客户端库,而不需要框架;处理程序可以使单独的程序,也可以嵌入到已有的服务程序中,可以选择自己想要的部署方式,而其他的流计算框架需要部署和运维一套框架,处理程序运行在框架中;
- 发明了一套流和表的理论,类似数据库日志和数据表一样,流代表了随时间推进的修改日志,表则是流聚合以后的最终状态视图。Kafka Stream通过提供KStream和KTable接口,为有状态的流处理提供了方便的编程模型。
功能上,除了分布式系统应该具备的高性能和可靠性,Kafka Stream有以下流计算的特点:
- 支持流的持久化和可重放;
- 支持有状态的流处理,包括分布式Join、聚合等;
- 支持流和表两种视图;
- 提供流处理的DSL,如
map,filter,reduce等操作;
如果已经选择了Kafka作为消息中间件,同时也需要做一些流计算,那么Kafka是一个不错的选择。
参考
(END)