Hadoop
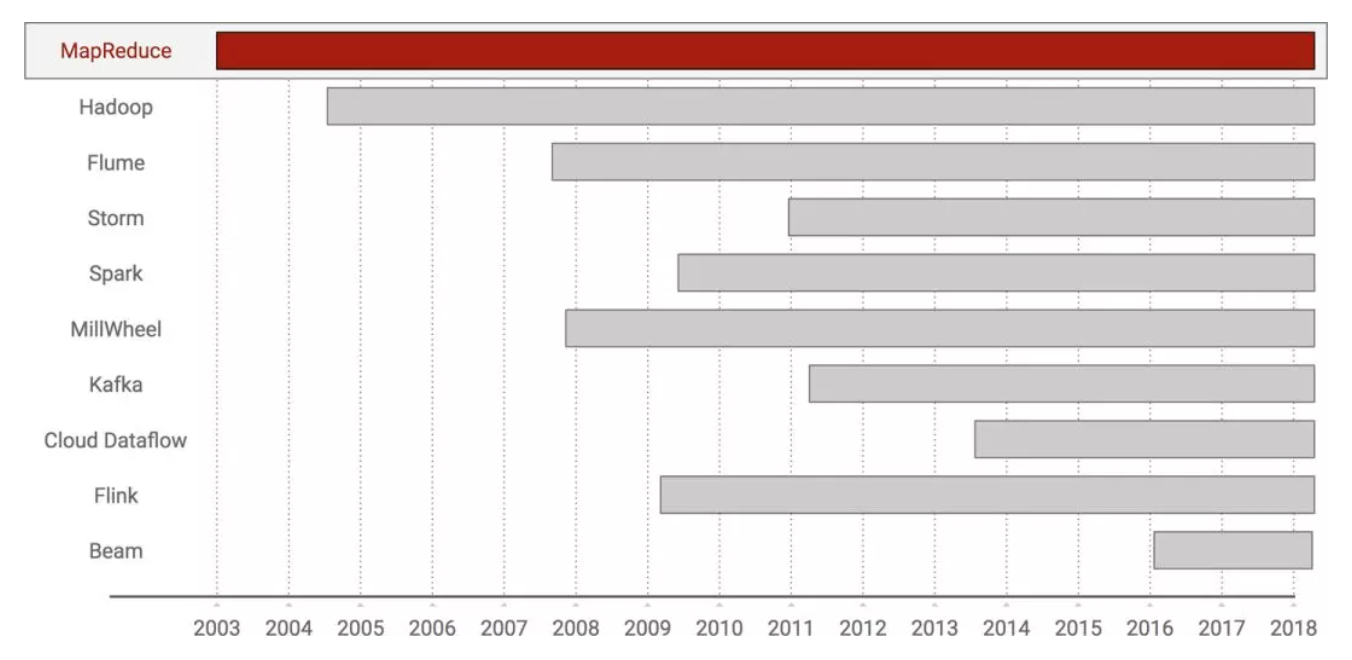
2003年Google的研发团队发表了 MapReduce 论文,开启了大数据处理框架的发展史。MapReduce是一套编程模型,模型设计的目的是,把耗时的大数据大任务拆解到多台普通的计算机器上并行计算,从而提高执行效率。
追溯大数据领域技术发展史,Google工程师团队发现要处理大数据数据,有两个方面的工作难题,
- 如何利用统计学甚至机器学习方法,构建数据模型,提供业务价值;
- 如何构建一套可复用的环境,更加高效地运行这些数学模型。
前者与业务紧密相关,而后者是可以工程化的。于是历史上有了Google对外发布的三篇论文,分别详细描述了Google的内部系统GFS、MapReduce和BigTable的设计,这三个Google内部系统用于将爬虫获取到的海量网页数据,进行索引和存储。
从此,大数据领域的相关的技术和工具就像雨后竹笋,蓬勃发展起来,
Hadoop的构成
今天大数据领域的技术,被使用得最广泛的是开源的Apache Hadoop。Hadoop的核心组件包括HDFS、YARN、Hadoop MapReduce,围绕这三大核心组件,又衍生出了一系列Hadoop生态系统,
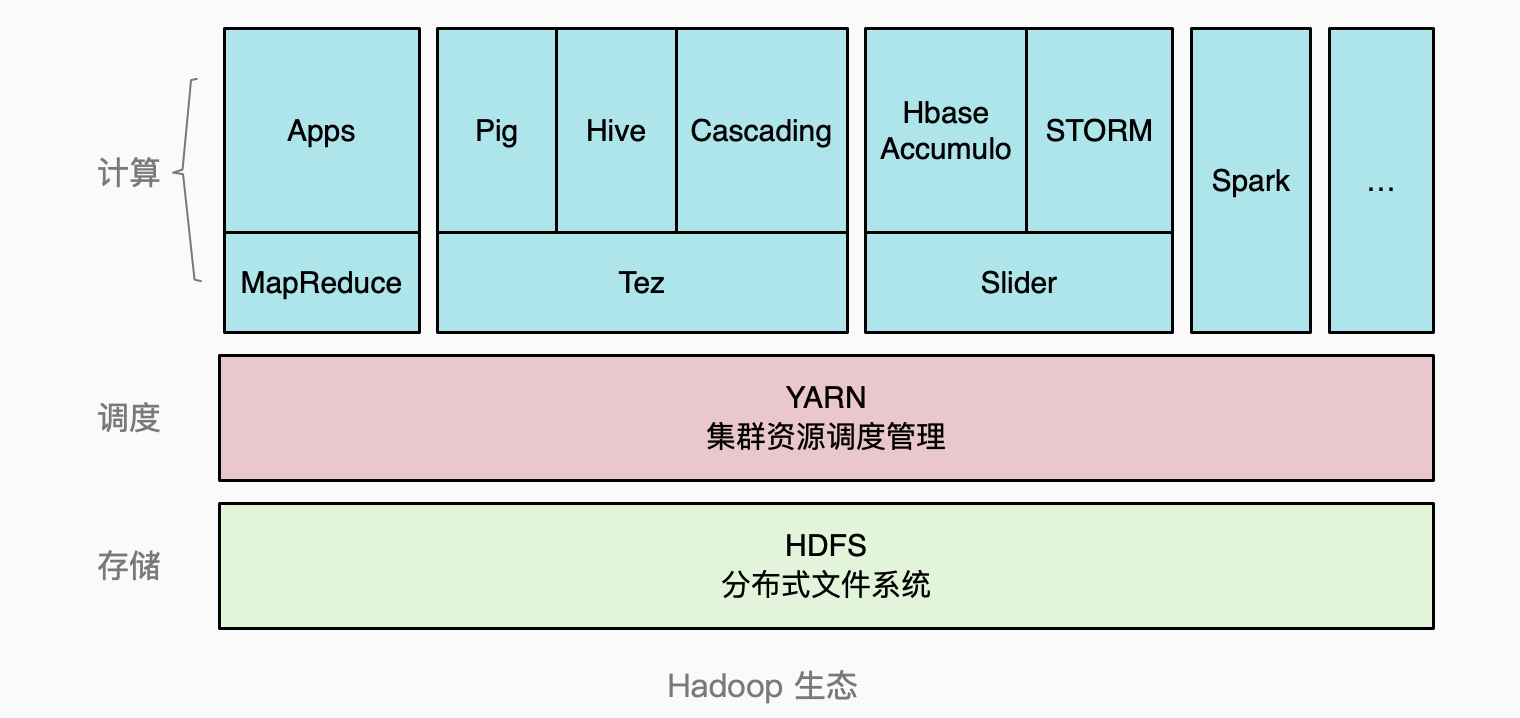
HDFS
HDFS(Hadoop Distributed File System )是一个运行在跨多台普通计算机上的文件系统。HDFS屏蔽了底层硬件和分布式系统相关的细节,为上层应用提供了一个可伸缩(无限扩容)、高可用、具有错误容忍性的文件系统。HDFS作为Hadoop整个生态的最底层基础设施,解决了非结构化数据文件的海量存储问题。
HDFS架构
HDFS采用了Master-Slave系统架构,
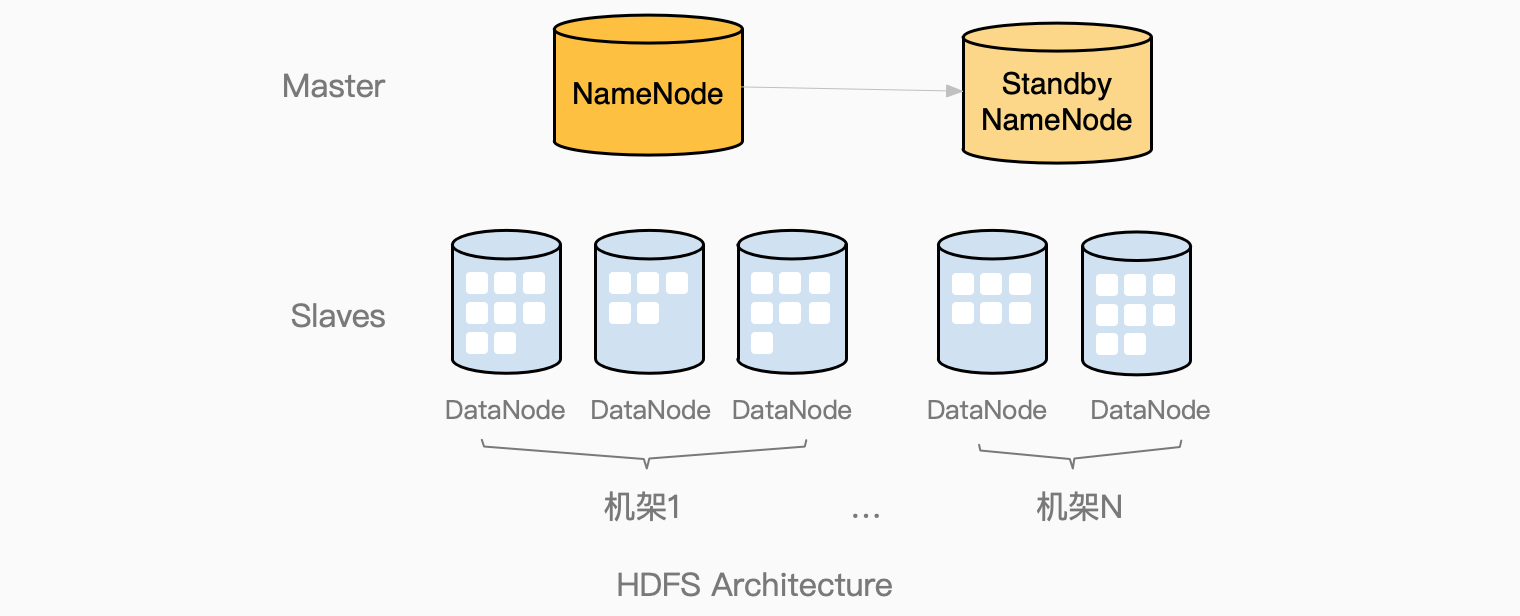
NameNode是所有节点唯一的Master,主要职能包括:
- 存储文件系统命名空间(目录和文件名),执行命名空间的管理工作;
- 指引Client去到对应的DataNode进行数据读写;
- 监控DataNode发回来的心跳,根据DataNode的健康状态,从而调度数据在DataNode上进行复制。
Standby NameNode作为NameNode的备用节点,用于解决NameNode的单点失败问题。开启HA模式后,当Active NN(NameNode)出现故障时,系统会自动切换到Standby NN。Active NN与Standby NN同步全部元数据,具有强一致性。
HDFS还支持一种叫做Secondary NameNode,Secondary NN 不支持故障自动切换,当Active NN故障时,需要手动切换到Secondary NN。Secondary和Standby 只能二选一。
DataNode是架构中的Slave节点,负责最终数据存储和管理(读取,创建,删除,复制)。HDFS把要存储的文件,切分为大小(默认128兆)相等的块进行存储,理论上可以存储无限大的文件,
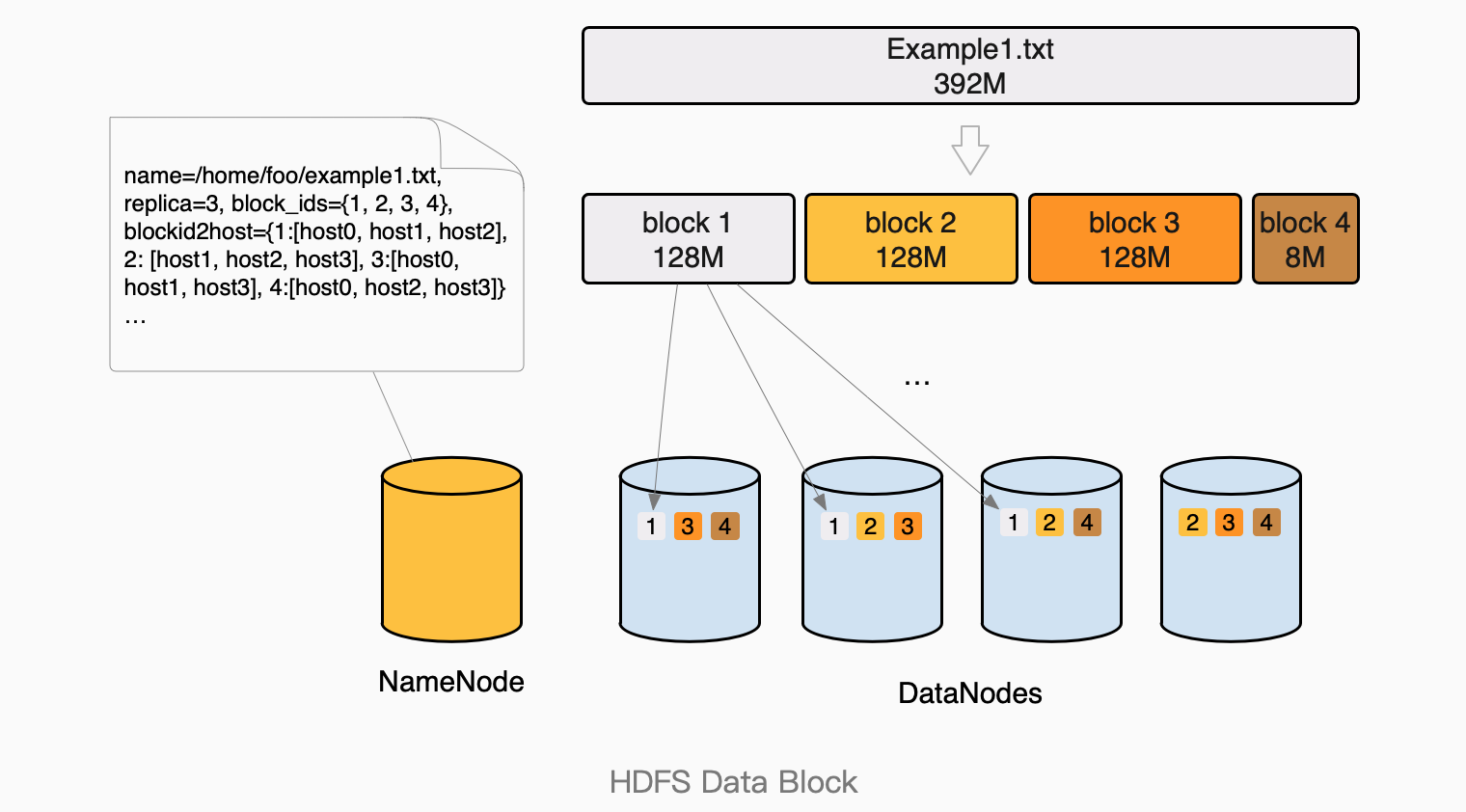
同时每一个块会被复制到多个(默认3个)DataNode上进行冗余存储,让HDFS具备高容错性(即使部分节点失败也不会丢失数据)。通过这样的系统架构和块存储的设计,让HDFS具备了存储容量的可伸缩性,及高容错性。
HDFS如何写入数据
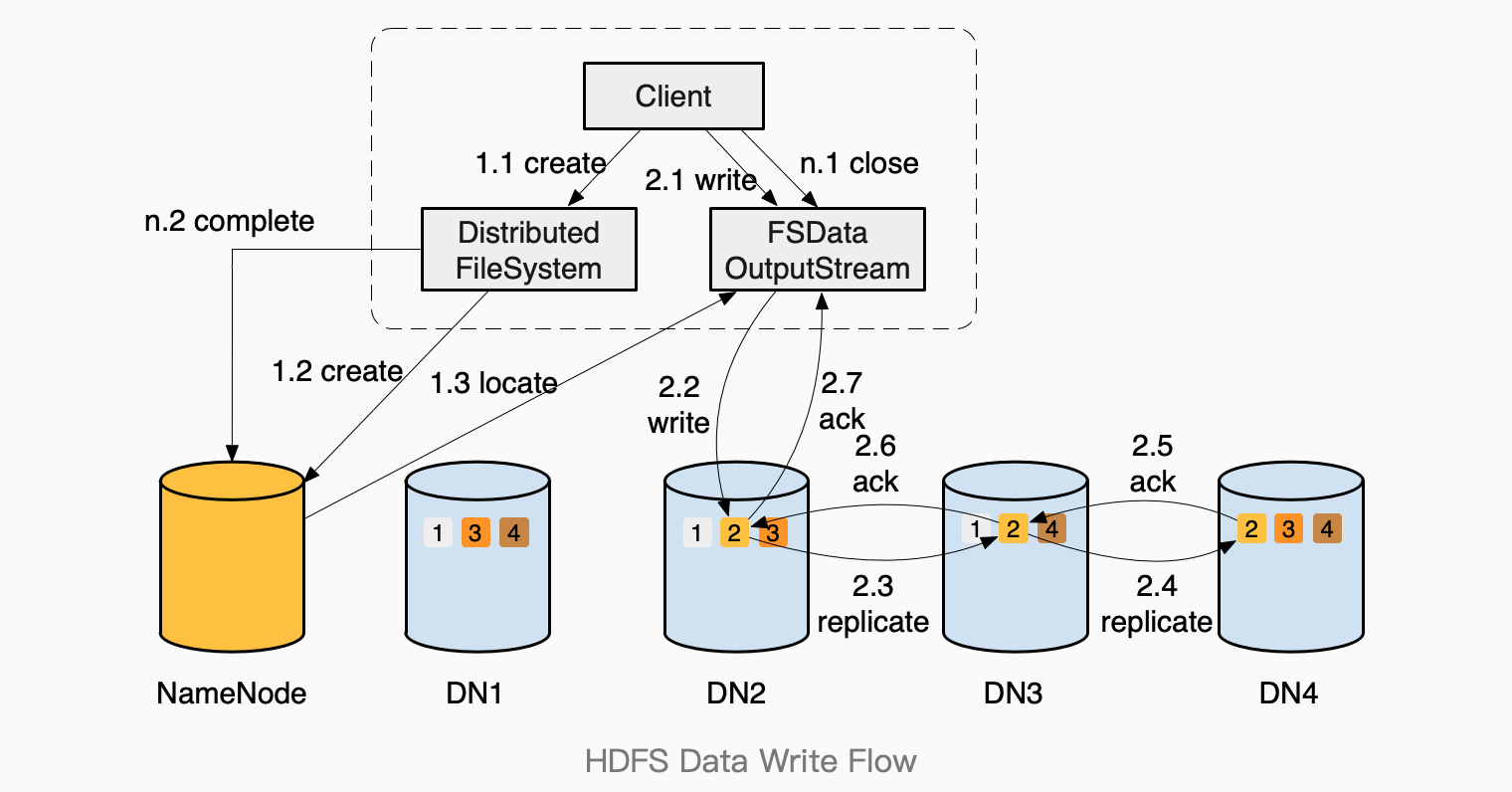
结合数据块的设计,HDFS写入一个文件数据流程大致如下:
- Client 联系NameNode,获取用于存放文件第一个block的DataNodes列表,一共返回 dfs.replication(默认设置为3)个DN地址;
- Client组织进行block写入的Pipeline(如上图),
- tcp连接到DN2,开始往DN2写入block,
- DN2接收数据的同时,新建线程tcp连接到DN3,复制写入block;
- DN3接收数据的同时,新建线程tcp连接到DN4,复制写入block;
- … 一直传递到 dfs.replication个DN上;
- 但只要有dfs.replication.min (默认设置为1)个DN响应了ack,就可以给Client返回写入成功了,剩下没完成的复制会继续异步复制下去。
- Client完成了文件的第一个Block的写入后,重新联系NameNode,获取存放第二个Block的DataNodes;重复上面过程,直到文件写完。
HDFS高可用
分布式系统架构中,Master-Slave模型相对简单,但Master的单点故障问题是整个系统HA的核心问题。HDFS Active NN可能因为断电、网络异常、负载过高或者机器出现异常无法连接,解决NameNode的高可用问题是实现HDFS HA的核心问题。有两个实现难点,
- 如何让Active NN和Standby NN的元数据保持完全同步(一致性);
- Active NN发生故障时,如何实现自动故障转移。
HDFS 使用了一个叫做 QJM(Quorum Journal Manager)的方案来实现让Active NN和Stanby NN的元数据保持完全同步。
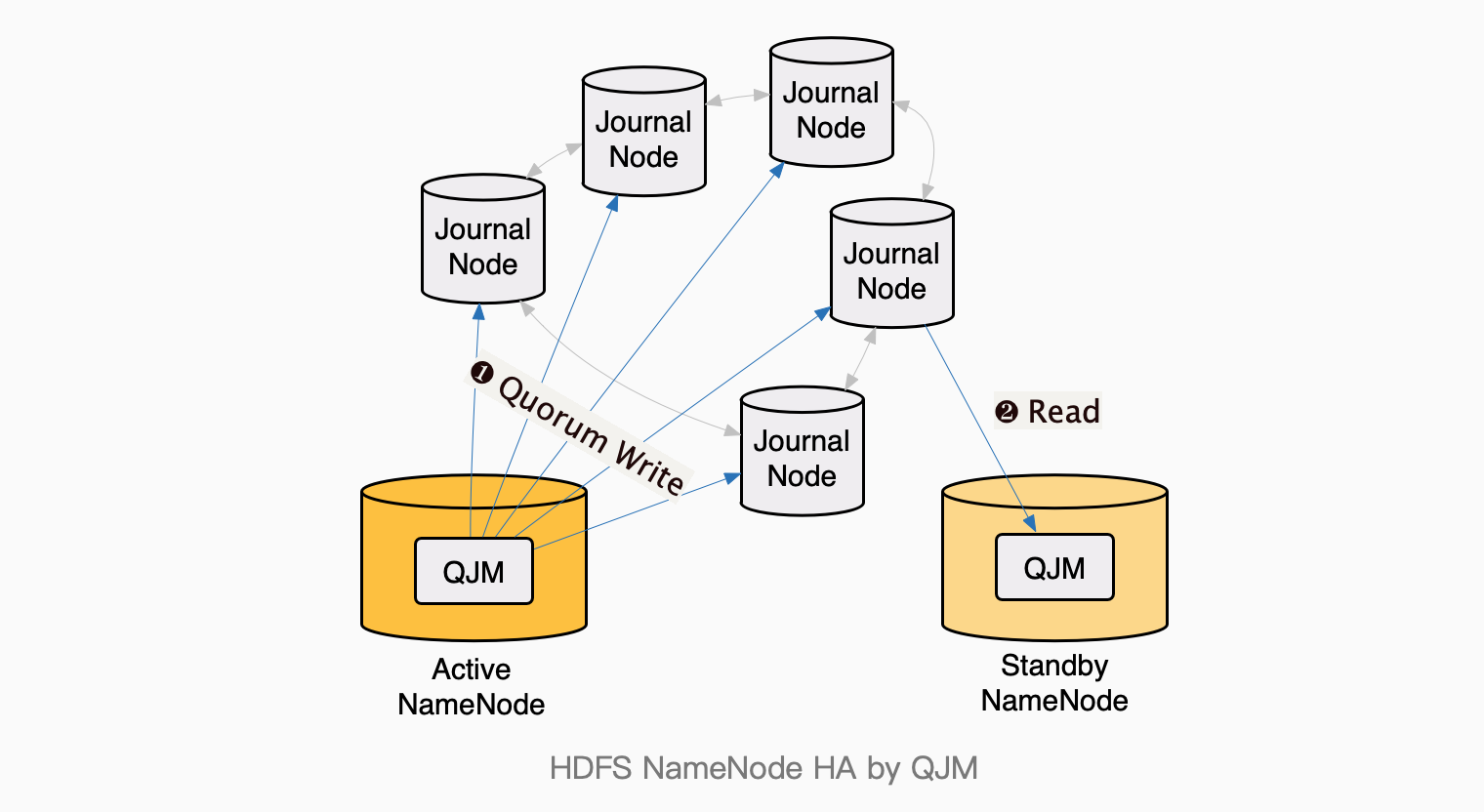
QJM自身是一个高可用的分布式系统,采用Peer-to-peer的架构,能够容忍(N-1)/2的节点故障。每一个JN(Journal Node)上都存储了NameNode的数据副本,每一次Active NN都并行地写入全部N个JN,当N中的大多数(过半)成功响应后,Active NN就认为写入成功了;而后Stanby NN可以从任意一个JN上读取数据。
QJM借鉴了Paxos和ZAB的共识算法,在多个JN之间达成“同一时刻只有一个最大的epoch”的共识,要求拥有最大epoch的NN才能够写入JNs,保障了同一时刻只有一个NameNode可以写入JNs,从而简化并实现了Active NN与Standby NN之间的一致性问题。更多细节可以参考QJM。
HDFS 设计了ZKFC(ZooKeeper Failover Controller) 进程,结合ZooKeeper的分布式锁来实现故障自动转移。
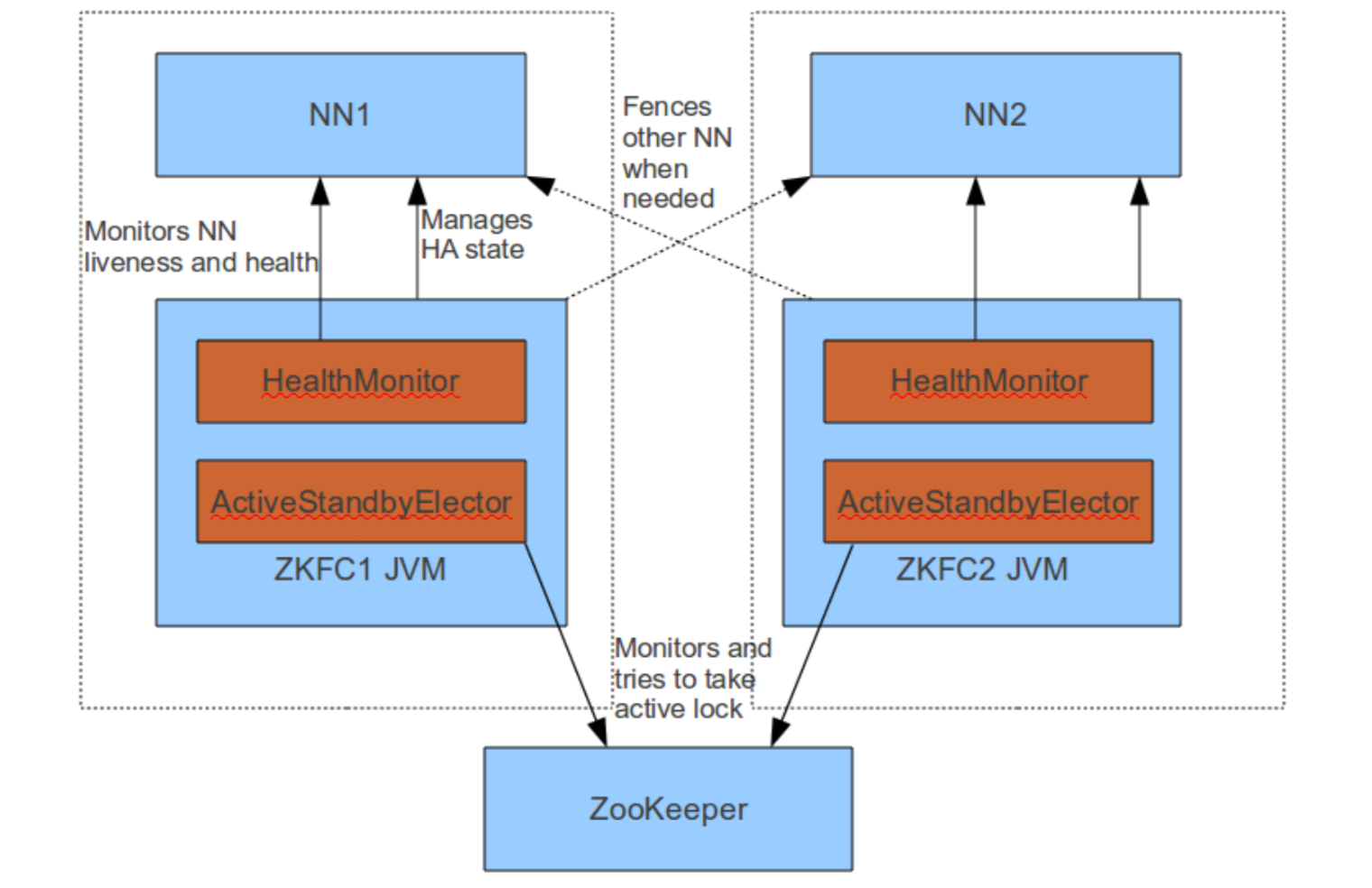
当一个NameNode成为Active状态时,它利用ZooKeeper创建一个锁(znode);当Active NN出现失败或连接超时的情况下,锁超时自动删除,这时Standby上的ZKFC进程就会重新抢占锁,从而让Standby NN切换为Active状态。更多参考ZKFC。
HDFS高级特性
HDFS除了可伸缩性(无限扩容)、高可用、具有错误容忍性,还具备一些高级特性,例如,
- 机架感知 当Client准备写入HDFS时,向NameNode询问可以写入的DataNodes列表时,NN通过一个算法策略,来选择返回哪些DataNodes给Client。其中一种策略是根据DataNode服务器所在的机架物理位置来决策的。这是一个HDFS的特点,能够带来以下好处,
- 数据分布到不同的物理机架,具备更高的可靠性;
- Replicas放到相近的机架,可以提高写复制和读的性能;
- 通过机架位置,优化MapReduce的Job发生的位置,从而提高计算速度;
- 纠删码冗余存储 HDFS默认数据备份3份,数据的存储效率是1/3,当数据量比较大的时候,对存储空间的消耗会比较严重,不经济。纠删码 (Erasure Coding) 可以通过只多冗余存储一小部分数据,获得相同的容错性。技术原理是通过增加校验位冗余数据,来提高数据的恢复能力,可参考EC in hadoop 3.0。
MapReduce
MapReduce如何工作
MapReduce六大处理过程,Input, Split, Map, Shuffle,Reduce,Finalize
Data Locality in MapReduce
MapReduce的局限性
MapReduce的替代者
YARN
Hadoop遇到的挑战
容器和云
流计算
总结
参考
- 开启大数据时代的Google三架马车 马车1、马车2、马车3
- Hadoop真的要死了吗
(END)