认识大数据
伴随移动互联网、IoT和5G的发展,数字世界的数据体量正在发生爆炸性增长,已经迈入了用ZB(1 Zettabyte = 1024 * 1024 * 1024 TB)这个单位来计量的时代。据IDC统计,在这些数据中超过95%的数据是无关联非结构化数据,这意味着如果不对这些数据加以挖掘和整理,即使使用云存储下来,它们也毫无价值,会和时间一样流逝。
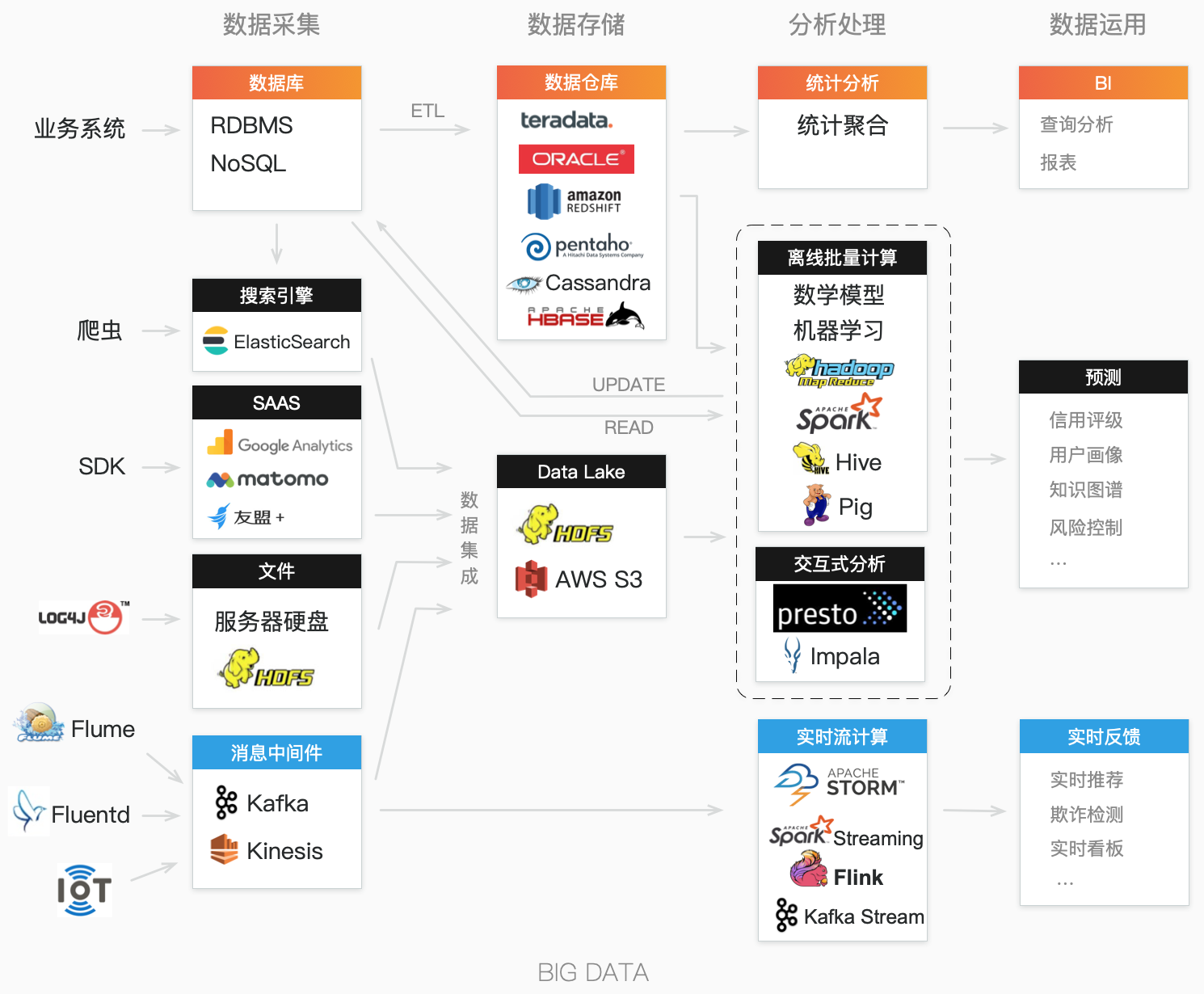
大数据是一系列更快更有效挖掘数据价值的相关技术。与传统的数据处理(OLTP/OLAP)相比,大数据有更长的生命周期,周期中的每个阶段都有不同的技术体系和工作目标,大数据处理主要分为四个阶段:数据采集,数据存储,分析处理,和数据运用。
数据采集
大数据采集工作是要把数据收集,预处理,然后存储起来。
大数据有两个主要特点,多元和海量,也就是来自很多源头的海量数据。这些数据除了来自业务系统自身的业务数据,还有其他各类日志和外部数据。业务数据在系统设计时,就已经明确的进行了语义和结构化的定义,一般存储在RDBMS或NoSQL等数据库中。而日志数据和外部数据,大多未能事先确定数据结构(半结构化甚至未结构化),如以下这些,
- 用户访问行为数据,如Web上的点击统计,APP上的各类埋点;
- 服务端日志数据,包括系统日志、访问日志等各类日志文件;
- 外部数据,泛指未能预先进行设计干预的数据,如爬虫抓取取回来网页等。
数据采集的核心工作是在”集”上,通常叫做数据集成,集成的过程包括,
- 定义数据标准,数据字典,数据结构;
- 梳理数据产生和流转流程,通过技术进行连接;
- 最后运用ETL工具,把不同地方的数据源,加载到相同的数据存储中。
这也是企业构建数据中台的必要工作,通过跨部门合作,对业务进行梳理,把原来分散的、未结构化的、结构化但格式不相同的各类数据打通,消除数据孤岛,进而发掘价值。也如IBM的定义,
数据集成是技术和业务流程的组合,用于将来自不同来源的数据组合成有意义的和有价值的信息。
数据集成可以是自己架设方案,也可以用一些完整的解决方案,可参考AWS Data Lake Formation、IBM DataStage。
数据存储
数据采集的目的是把数据集中化的存储到数据仓库或数据湖。
数据仓库(Data Warehouse)和数据湖(Data Lake)有一些重要的区别,
| 数据仓库 | 数据湖 | |
|---|---|---|
| 内容 | 数据主要来自原始业务数据,经过ETL后的结构化数据。 | 来自各类日志文件、外部数据、IoT日志等等,可以是不经过ETL未结构化的数据。 |
| 质量 | 准确的结构化数据 | 数据未经加工,半结构化、未结构化的原始数据 |
| 存储在哪儿 | 一般采用Data Warehouse 列数据库(拥有更加高效的统计聚合效率)。 | 具有弹性扩展能力的分布式文件系统,如HDFS、AWS S3。 |
| 使用者 | 数据分析师 | 数据科学家、数据挖掘工程师 |
| 数据用途 | 分析查询、报表 | 数据挖掘、机器学习 |
分析处理
大数据分析处理的数据范围,不仅包含数据湖的文件数据,也会使用业务数据库和数据仓库。通过分析处理得到的有价值数据,又更新回到业务数据库或数据仓库,从而形成数据闭环,不断优化,为业务提供支持。
如何更快的处理数据,是大数据技术的重要方向之一。不同场景对处理时效有不同的要求,从离线批量计算到实时流计算,相关的计算框架也在不断的演进,
-
离线批量计算
批量计算处理以天、周、或更长时间周期的累计数据,需要使用并行计算框架来提高执行效率。但由于数据量大,执行时间往往仍然需要几十分钟到几小时(取决于数据量大小)。
Hadoop是最常用的大数据并行计算框架,它包含HDFS分布式文件系统和MapReduce编程架构两个部分。MapReduce把待处理数据拆分为多份小数据,分配到多个计算节点上进行计算,分别完成后最终再合并计算结果。
Spark作为MapReduce的一种替代,通过在RAM中存储和合并中间结果,以获得更快的运算速度。
-
实时流计算
流的特点是持续不断和小数据量,和流水一样。数据以小文件流的形式持续不断的流入,计算任务仅处理单条数据(或小批量数据),以几乎实时的时效完成计算。为此,需要两个强大的支撑组件,流存储系统和流计算系统,
- 流存储系统,具备高吞吐低延迟的特性,保障消息不丢失,实时的传送给流计算系统,如Kafka、Kinesis;
- 流计算系统,具备弹性伸缩的特性,可靠地管理分布式任务线程,提供无限计算能力,如STORM、Spark streaming、Flink、Kafka Stream。
如何更有效的挖掘数据价值,是另一个大数据技术的重要方向。从相对简单的统计聚合算法,发展到了利用数学模型来做分析处理。
机器学习是数据挖掘和人工智能的热门数据处理技术。依靠分类、回归、聚类等统计学算法,使用大量历史数据作为训练样本,以及结合特征工程,完成数学模型的构建,最后利用这个模型对未来数据进行预测。
早期人工数据建模,模型的优化和验证需要经过漫长周期。现在利用机器学习,不仅可以极大缩短时间,同时也减小了人工操作成本。
现在要进行机器学习的任务,有很多流行框架和Lib,包括TensorFlow、Torch、Caffe、Theano、Scikit-learn,也有如Amazon ML的完整解决方案。
数据运用
传统的运用主要集中在BI及数据可视化领域,现在大数据和机器学习的结合,已成为解决以下领域问题的关键技术:
- 金融,用于信用评估和算法交易;
- 图像处理和计算机视觉,用于人脸识别、运动检测和对象检测;
- 生物,用于肿瘤检测、药物发现和 DNA 序列分析;
- 自然语言处理,用于语音识别相关运用。
曾经,算法被认为是实现人工智能的关键,而如今,大数据和机器学习占据了主导地位。
相关岗位
对应大数据的各个环节,目前市场需求主要是以下这些职位为主,
- 数据科学家,负责模型设计,偏学术化;
- 数据挖掘工程师,负责数据收集,ETL,模型工程化,和算法实现;
- 数据产品经理,结合业务数据和行业数据,规划和设计产品;
- 数据分析师,结合业务数据和行业数据,形成分析报表,辅助决策层。
未来,随着云的进一步渗透,和大数据的广泛运用,首当其冲的一定是数据的安全和用户隐私问题,所以未来也也会产生很多和云、数据安全的相关岗位。
总结
大数据是对这个领域的一种感性认识和表述,数据科学是另一种更学术的叫法。数据科学不是一个独立的学科体系,它交叉跨越了云、数据库、分布式计算、统计学、机器学习、信息可视化等知识领域,是挖掘数据价值的一系列技术和方法。
最后,把所有处理过程放在一起,可更清楚地认识大数据。
(END)