Flume数据采集系统
在进行大数据采集和数据集成时,我们期望有一个统一的工具来收集各种不同的数据源,然后发送到集中存储,Apache Flume就是这样一个强大的数据采集工具。
Flume通常以一个独立的进程,运行在待数据采集的节点上,这个进程叫Agent。
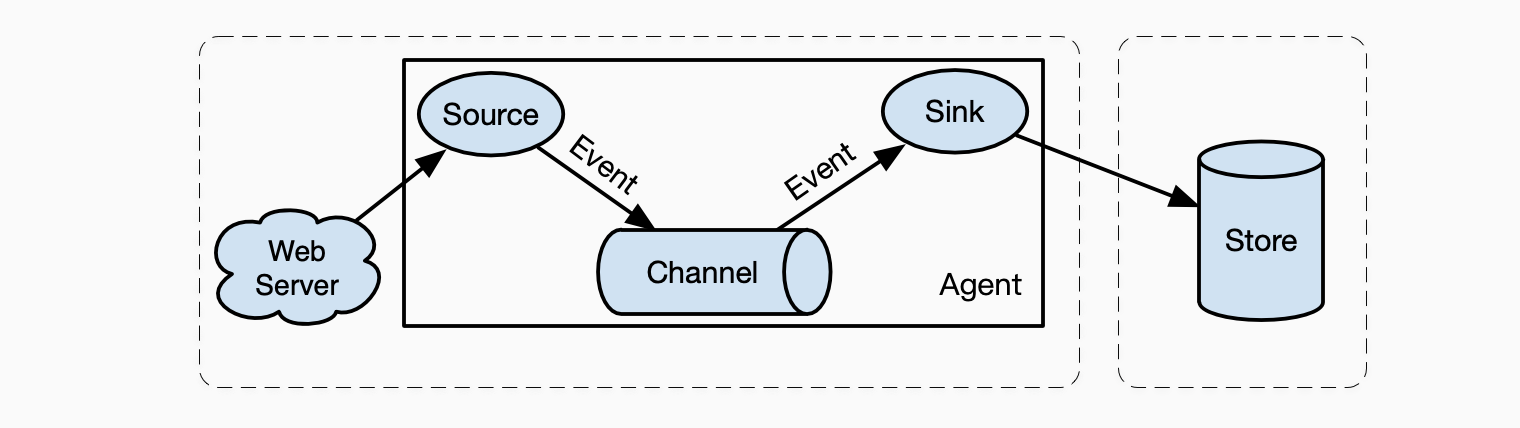
Flume组件
Flume由四个核心组件构成,
- Source,从外部数据源被动接收或者主动捕捉数据,能够解析各类数据格式以及通讯协议,获取到的数据封装为Flume的数据实体,暂存到Channel。目前支持的数据源包括:Avro、Exec、HTTP、Kafka、Spool Directory,等;
- Channel,作为数据的传输通道,先暂存数据,也支持持久化到硬盘文件或者Kafka。当数据被Sink传送到目的地后,再从Channel中删除数据,保障了数据的可靠性。同时,也解耦了数据的生产和消费。当前支持的暂存介质包含:File、Kafka、Memory(故障后不能恢复);
- Sink,从Channel中取出数据,然后根据目的地需要的数据格式进行序列化,最后完成数据的传输。目前Sink支持的目的地包括:Avro、HDFS、Hbase、ElasticSearch、Kafka、HTTP,等;
- Event,Event是Flume中数据流通的结构定义。在Source端,数据以Event的格式被生产,然后以Event的格式序列化后暂存在Channel中,通过Sink把Event再序列化成目的地的数据格式,完成数据传输。Event由一个headers HashMap和body构成,
{ headers:{timestamp=1346485898919, host=ip-10-34-4-55.ec2.internal} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. }
Flume的这种Source-Channel-Sink的设计模式,让每个组件都保持职责单一,具有良好的扩展性,未来也可以实现更多的数据源接入和目的地传输的支持。
除了上面四个核心组件,下面三个组件为Flume赋予了更高级的特性,
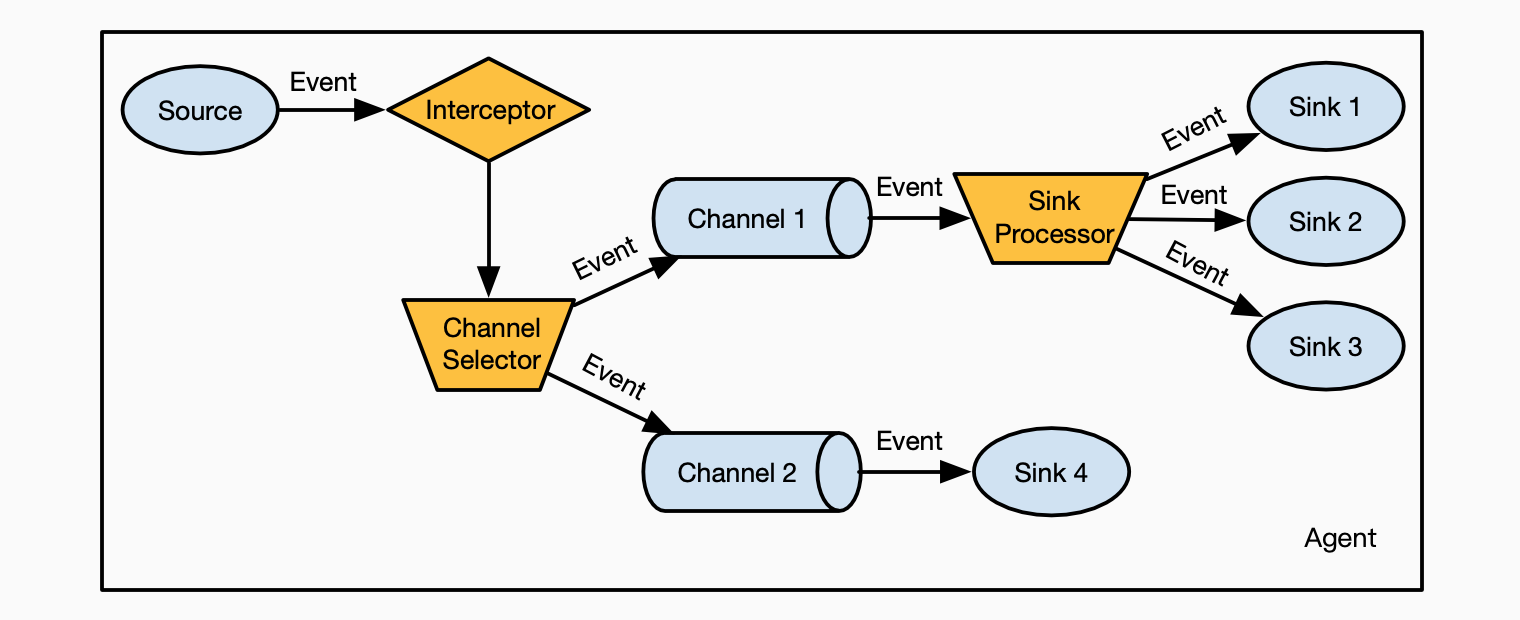
- Interceptor,数据拦截器,拦截器可以通过设定的条件拦截Event数据,对数据进行修改,甚至丢弃数据。同时可以设置多个拦截器,串联在一起,一层一层的处理数据。例如,在数据header中追加当前节点的IP地址,追加数据采集时间戳,等等;
- Channel Selector,同一个Agent可以有多个Channel来暂存数据。Source产生的Event数据,默认会将它复制到配置的每一个Channel,也可以通过设置,选择性的复制到部分Channel;
- Sink Processor,多个Sink可以绑定到同一个Channel,这时选择哪一个Sink来传送Event数据,就可以通过设置Sink Processor(failover或load_balance)来进行路由。failover可以让Flume把有故障的sink排除,让具有第二优先级的sink来接替工作;load_balance可以在多个sink之间,提供负载均衡的特性。
主要应用场景
一、服务器日志采集
如今有很多能够收集和存储日志的解决方案,但Flume拥有独特的的优势:
- 透明性,无需修改现有系统和架构,支持多种数据格式和通讯协议,直接抓取或适配现有数据;
- 灵活性,通过配置就可以现有适应复杂的系统架构;
- 分布式Agent,无中心化问题。
相同数据协议的两个Agent,可以首尾相连,让数据能够流动起来,
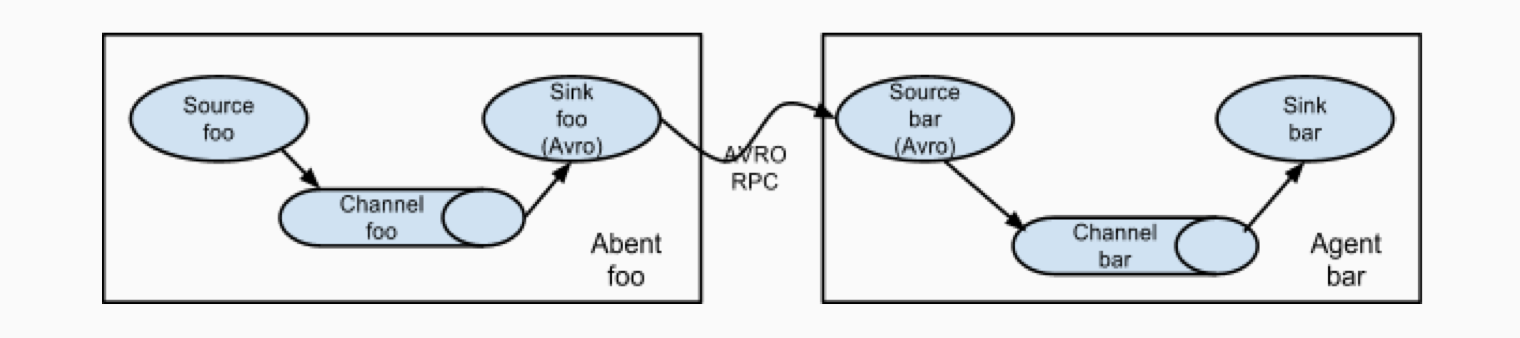
这个特性在实际的场景中得到了广泛的运用。例如,上百台Web实例上都运行了Flume Agent用于Web访问日志的采集,通过连接Agent,把数据汇聚到小部分的Agent,最终通过这小部分的Agent(HDFS Sink)写入到HDFS存储中。
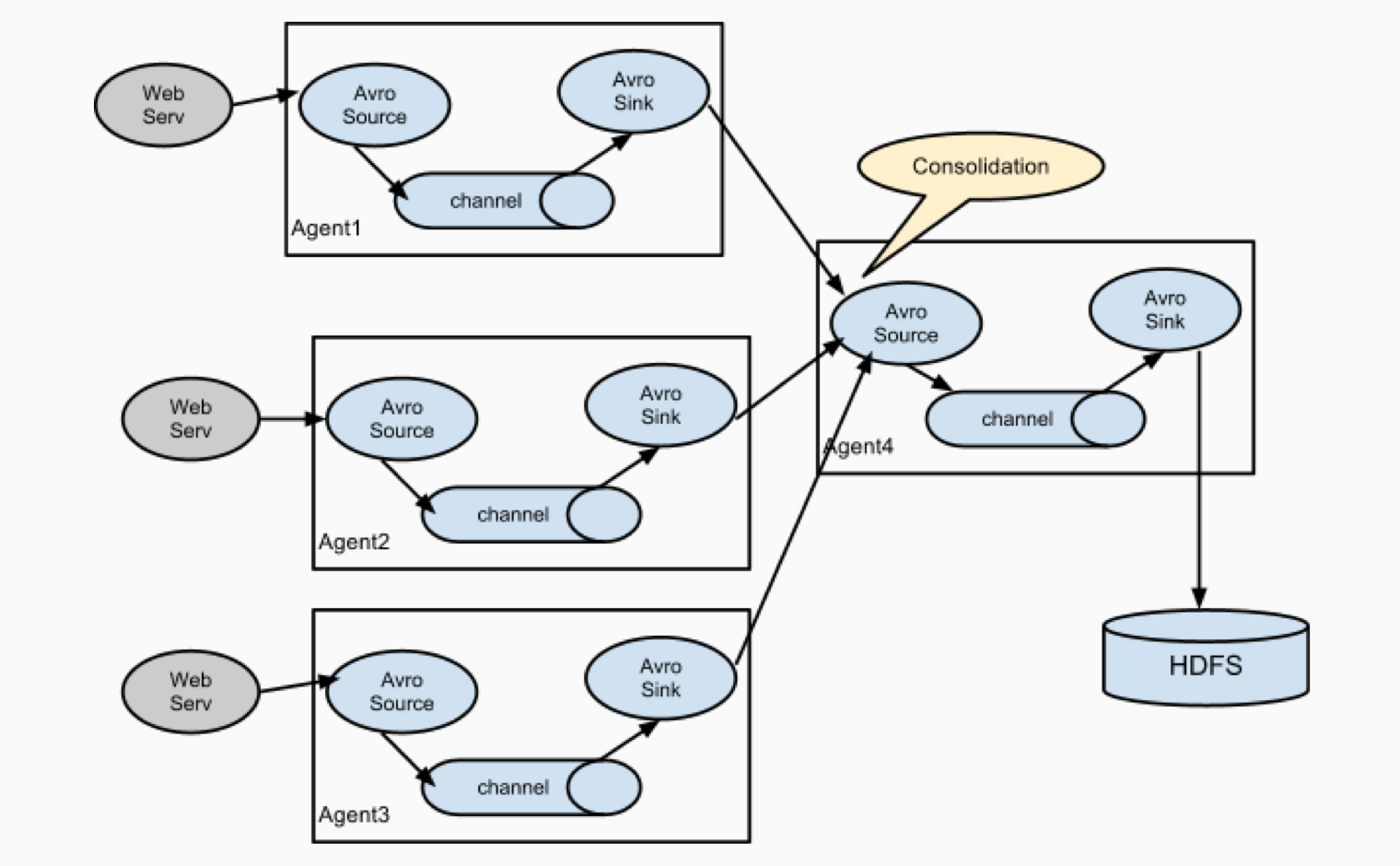
二、保障数据可靠性
对于Flume的数据流,可靠性主要取决于三个因素,
- 选择哪一种类型的Channel来暂存数据
- Channel的可靠性和负载能力
- 是否采用了数据冗余相关技术
Channel的可靠性和可恢复性决定了Flume的可靠性。目前Channel有三种选项:
- 内存(无可靠性,进程失败或者宕机后数据丢失);
- 本地文件(宕机后数据不可访问);
- Kafka Channel(高可用);
利用Kafka作为Flume的Channel,可以获得Kafka的高可用特性,解决对有数据有高可用要求的场景,
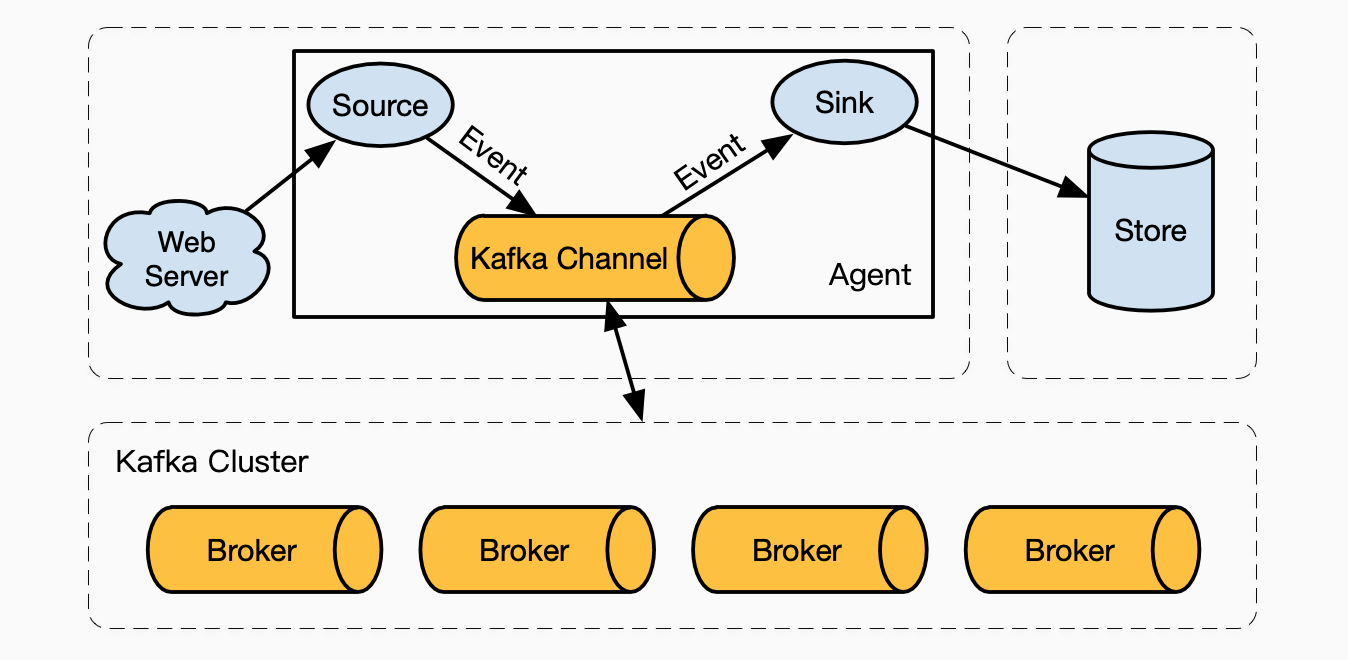
三、配合Kafka使用
实际运用中常常看到Flume和Kafka同时出现。
Kafka除了可以作为Flume的Channel来增加可靠性。同时,由于Flume提供了支持Kafka的Source和Sink,所以Flume也常作为Kafka消息的生产者和消费者,
-
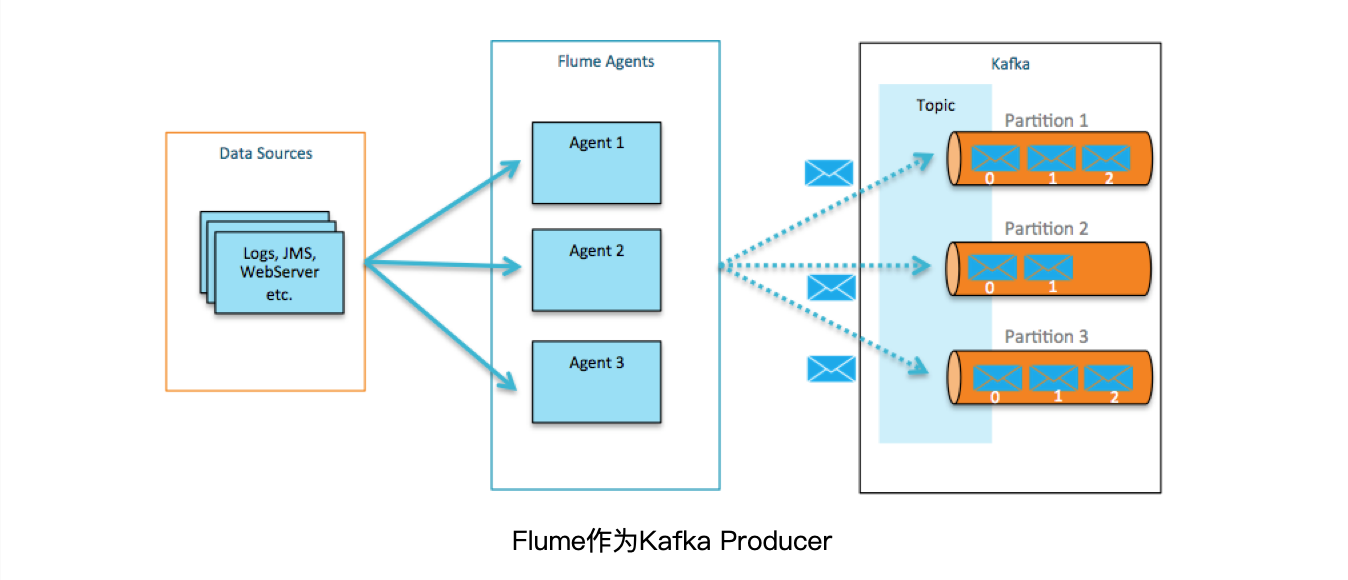
使用Flume来采集不同的数据源,同时作为Kafka消息的Producer,将消息实时投递到Kafka中。后续,Kafka可以把消息推送给实时流计算框架或其他的Consumer;
-
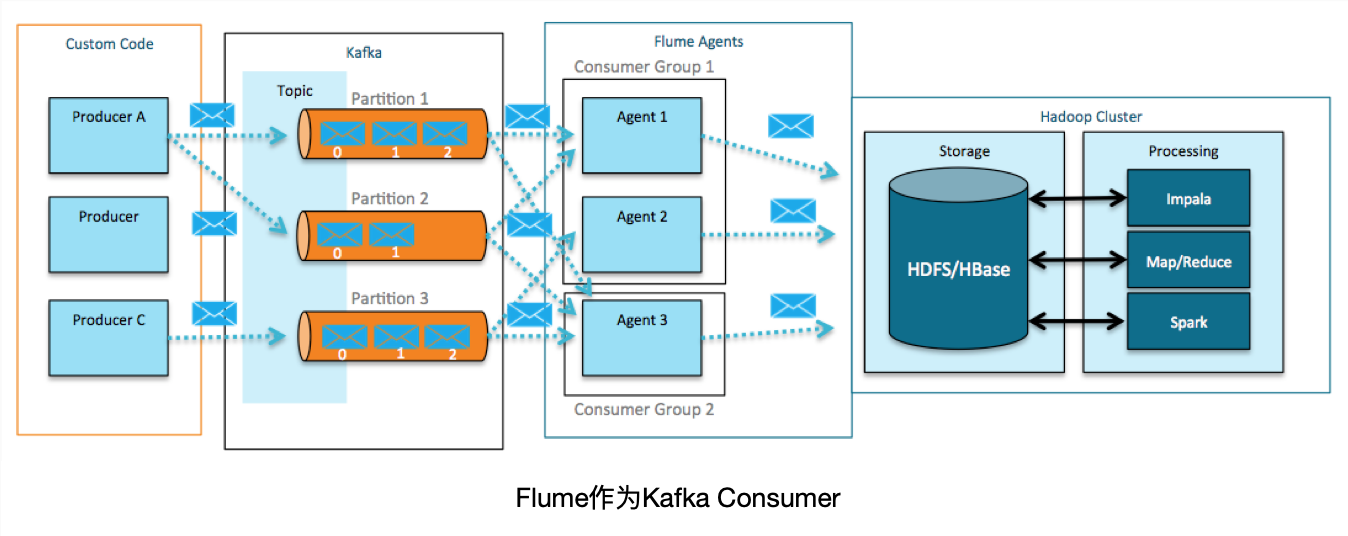
Kafka作为一个高可用的消息中间件,充当了一个消息池,常用于消除消息生产端和消费端速度的差异,解除两端的依赖性。 再利用Flume Sink将数据下沉到存储系统。
参考
- https://flume.apache.org/FlumeUserGuide.html
- https://blog.cloudera.com/blog/2014/11/flafka-apache-flume-meets-apache-kafka-for-event-processing/
(END)