分布式一致性
一切始于大,大量的用户访问,以及随之而来的大量数据存储和计算,让传统单机或All in one架构,无法再通过增加单台硬件配置,来提升性能满足需求。于是只能通过水平切分计算与存储,横向进行扩容,这就有了分布式系统。
分布式系统模型
分布在网络上的多个物理主机,通过消息传递相互协同来完成共同的任务,对外看起来像是一个整体的系统,叫做分布式系统。
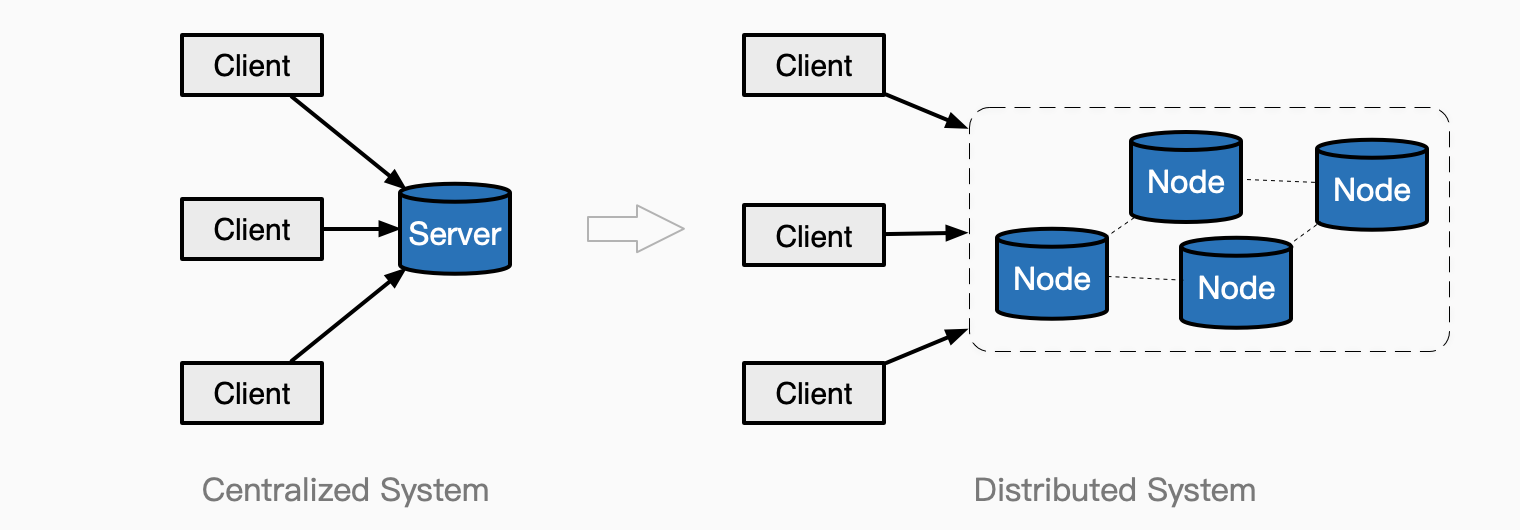
通过对计算和储存的切分,以实现分布式系统的核心目标:
-
高性能,实现水平扩容,获得高并发;
-
高可用,多副本(replication)实现容错,提高分区容忍性和可用性;
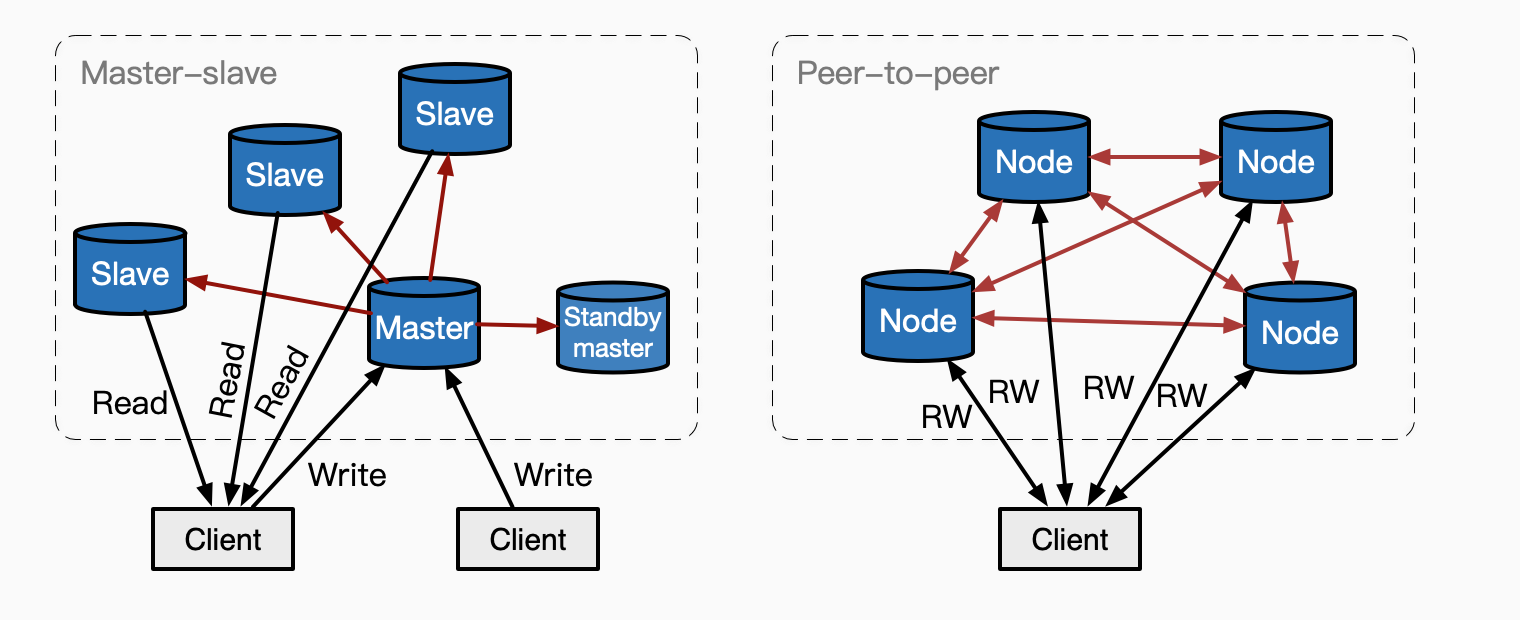
分布式系统内部,节点与节点之间,主要分为两种架构模型:
-
Master-slave
主从架构,所有写入都通过Master节点进行,Master再对其他节点进行数据同步;读取数据可以从Master,也可以从Slave,这取决于业务是否可以接受数据复制的延迟;
优点:架构简单,没有多写带来的数据冲突问题;
缺点:Master有单点失败风险,也有的性能瓶颈;
-
Peer-to-peer
P2P架构(也叫Leaderless),可以从任意节点进行读写,节点与节点之间进行数据的广播复制。
优点:消除了Master的中心化问题,更好的容错性;
缺点:实现复杂;
无论采用哪一种架构模型,分布式系统分布在网络上的多节点,因此也引入了一些新的具有挑战性的问题,主要涉及三个方面:
-
一、节点故障
节点自身和节点的接入网络都可能发生故障。导致这种故障的可能性很多,如硬件及网络问题、软件配置造成的不稳定、DDoS等等;归结起来,这些故障主要分为两类:
-
Fail-stop 故障停止,节点发生故障后对外表现为停止运行,这是最常见的故障模型;
-
Byzantine or arbitrary failures拜占庭或随机故障,节点向不同的观察者呈现不同的症状。故障检测机制也不能判定节点失败并将其排除,需要大部分节点达成共识后再将其排除。
-
-
二,通讯延迟
网络通过存在一定的延时,按照节点间通讯延时是否设定上限(timeout),把通讯分为两类:
- Synchronous model同步模型,消息有超时设定,超时则可立刻判定为通讯失败;
- Asynchronous model异步模型,发送方发送消息后立即返回,消息可能延迟任意长的时间到达。
延时是影响分布式一致性的核心因素之一,这两个通讯模型也是决定分布式强一致性和最终一致性的关键。
-
三、消息可靠性
分布式系统节点间传递的消息还可能出现各类可靠性问题,
- 错序,由于网络延迟和不确定性,即使同一节点发出的两个事件消息,也有可能错序;
- 无序,由于各个节点缺乏全局时钟(各节点即使通过NTP也不能拥有完全一样时间),无法判断整个系统中不同节点发生的事件的先后顺序;
- 消息也可能重复到达,被篡改,etc
如何和解决消息的可靠性,后面会介绍到一些相关的技术。
分布式一致性
分布式一致性(Consistency)是指分布式系统中同一个数据的多个副本(Replication),经过一系列读写操作后,其对外表现的一致性。
一致性可以实现到不同程度,不同实现程度的代价不同,根据实现程度分为如下三类,
- 强一致性,
- 线性一致性 Linearizable
- 顺序一致性 Sequential
- 弱一致性
- 最终一致性 Eventual
- 以及最终一致性的很多变种
- 不一致
强 vs 弱
强一致性的分布式系统,把整体(所有节点)看做一个黑盒,从黑盒内部视角,对于黑盒的每一次写入,所有节点都必须立刻(在写入返回之前)相互通讯并且达成共识完成同步,后续的对于黑盒的任何一次读,都会取得最近一次写入的值。
这也是为什么Strong Consistency又叫做Single-copy Consistency的原因,这个约定让分布式系统看起来和单副本系统一样。
然而,弱一致性不要求黑盒内部马上形成共识,不要求所有内部节点立刻同步。但是在一定的时间窗口或者条件之后,黑盒需要保证内部节点数据能够同步。这导致弱一致性的系统,每一次读不一定能够获得最近一次写入的值。
第三类不一致的情况也是存在的,如分布式缓存系统,为了获得极致的可用性和性能,会进一步在一致性上进行妥协,数据可能不会总是严格地在所有节点上同步。
强一致性的要求,会付出高延迟的代价,Client进程需要等待黑盒内部的数据同步才能够得到响应。所以,实际场景中,常常设计弱一致性系统,再结合一些补偿机制来保障数据的完整性。
线性一致性
线性一致性是一种强一致性,上面我们从系统内部的视角描述过强一致性。下面从Client客户端的视角来描述线性一致性,两种视角的要求是等价的。从Client客户端的视角,要求系统具备两点:
- 对于跨不同机器的所有Client进程的所有操作,系统表现得如同采用了全局时钟顺序,使得所有的读写操作都能够串行地执行;
- 在全局时钟顺序串行执行,意味着每一个操作响应结束后才能发起后续操作,最终,所有的读操作均能返回最近一次写操作的值;
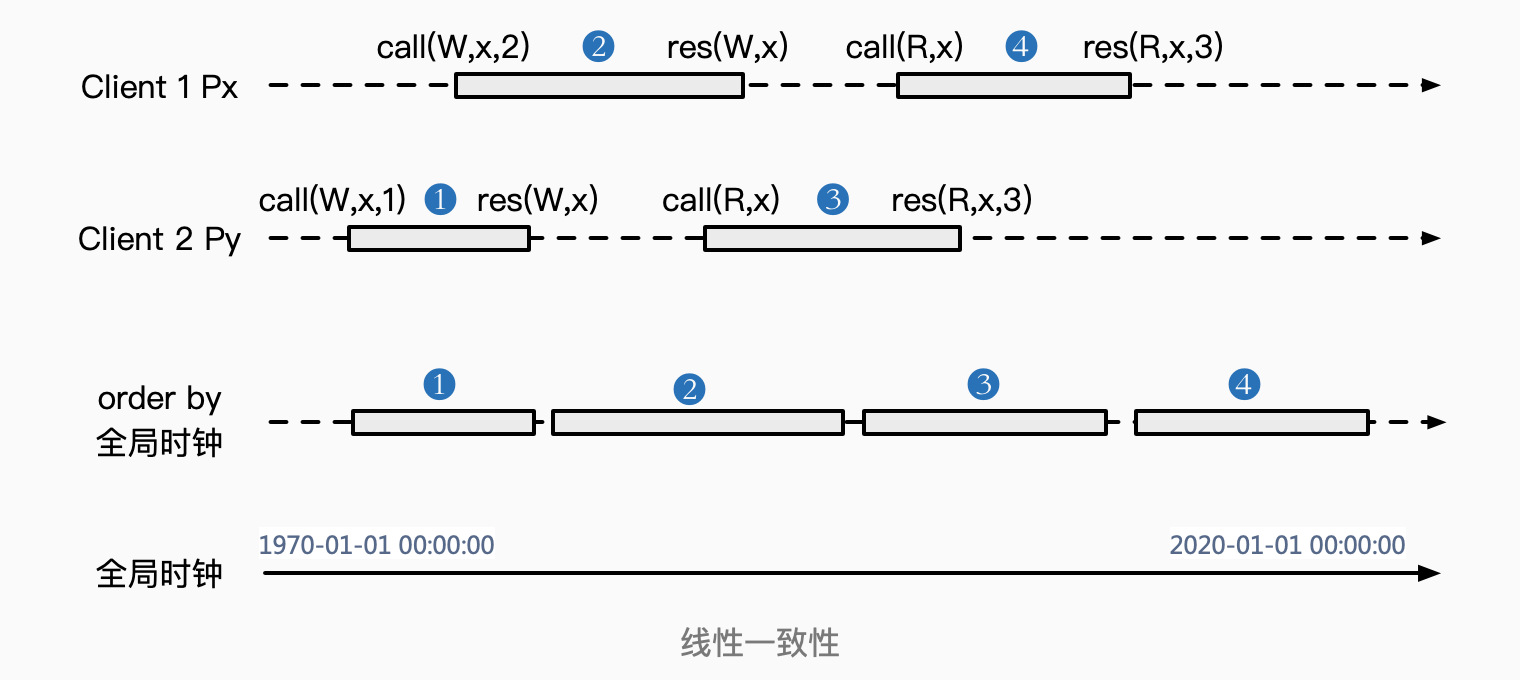
如图中不同Client机器上的进程Px和Py中,每一个操作都有一个唯一的全局时间,这样自然可以排列成一个不冲突的执行顺序,call❶->res❶->call❷->res❷->call❸->res❸->call❹->res❹,结果使得,每一个操作的返回时间点时,黑盒内部的副本都已经完成同步,那么下一个操作操作自然就一定会获得最新的值。
但不幸的是,世界上(不仅是分布式系统领域)不存在全局时钟用来进行全局排序,同时,任意内部副本节点之间的通讯网络不可能做到0延迟,所以线性一致性只是一个理论模型。
顺性一致性
相比线性一致性,顺序一致性放松了全局时钟时序的要求,但提出了另外两个关于操作顺序的要求,仍然从Client客户端的视角:
- 对于单个Client操作进程,进程内的事件执行顺序按照编程顺序(进程内可以通过共享时钟、内存等来实现先后顺序);
- 从Client观察者的角度,保证所有Client进程的所有操作事件,按照某种顺序串行起来,对于所有Client来说,都是这样同一个顺序。
因此,需要一个排序规则或算法,来达成这种顺序,让所有Client客户端操作串行顺序执行。向量时钟(Vector Clock)是一种常用的实现方式,不依赖于物理时钟,在离散系统中确定各个事件的发生次序(happen-before),并基于两两事件的关系,最后推导出整体次序(Total Ordering)。
在实际场景中的强一致性,都可以认为是指顺序一致性。例如,如果MySQL Master-slave设定为同步复制,那么则可认为这个系统满足顺序一致性。
最终一致性
如果系统没有新的更新,在一段时间之后,所有的副本的数据都会收敛到一致的状态,最终所有访问都将返回最后更新的值。
为了获得高可用性和高性能,最终一致性是今天大部分分布式系统的选择。因为在大部分的业务场景下,数据最终处于一致状态就足够了,而不是要求在每次事务之后要求立即一致。
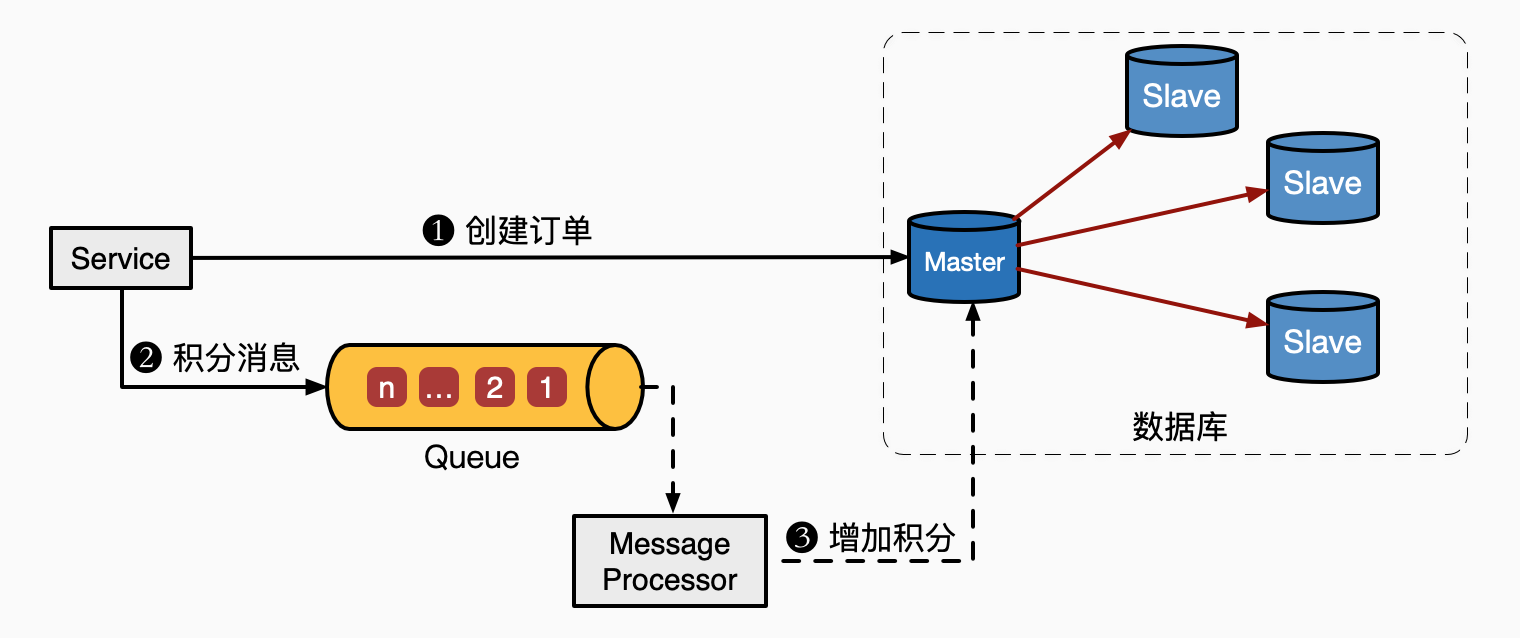
例如,用户创建订单❶成功以后,通过发送一个积分消息❷给消息队列,通过ACID事务让❶和❷同时成功或失败,保证业务的正确性;由于增加积分的过程❸并不简单,可能需要一些运算,同时订单创建完成这一瞬间,用户的关注点并不是积分的增加,而是订单是否成功。所以,业务上允许我们把增加积分❸异步处理,而不需要阻塞整个订单流程。也就是说用户积分满足最终一致性。
另外,对于数据库系统,Master和Slave之间也可以设置为异步同步模式,那这个时候整个数据库系统也满足最终一致性。
区别于ACID一致性
ACID中的一致性是指DBMS中的一次事务操作(事务中包含了一些列的读写操作),在执行前和执行后,需要保障业务数据的完整性和系统预设的约束。简单来讲就是要么全部成功,要么全部失败。
-
以银行两个账户之间转账为例,不会出现,转出账户已扣款,但转入账户却没增加的情况;
-
以MySQL的Master-Slave复制为例,你可以能会在Slave上发现,转出转入账户同时都更新了,或者同时都没有更新,但你不可能看到转入和转出不配对的情况。
所以ACID保障事务内一系列操作的后,数据库数据的正确性和完整性,是实现分布式数据库系统强一致性的一种技术。
CAP理论
CAP理论是分布式领域重要的系统设计指导原则,比较抽象的描绘了一致性、可用性和分区容忍性三者的关系,同时指出在系统设计时需要进行一些权衡。
定义
CAP理论推测并被证明了,分布式系统不能同时完全满足以下三个特性,
-
一致性(Consistency):上面已经详细介绍过了,表示副本节点数据的一致性状态;
-
可用性(Availability):每一次对系统的请求,都能在规定的时限内得到非错误的响应(即使获取的数据不是最新数据);
-
分区容错性(Partition tolerance):各节点组成的网络本开始是连通的,因为某些故障,使得一部分节点之间不连通了,整个网络就分成了几块区域,数据就分布到了这些不连通的区域中,这就叫分区。分区容忍就是即使由于网络或节点故障导致发生了分区,系统仍能够继续运行(怎么样运行就取决于C和A的权衡);

分区是分布式环境存在的客观条件,按照CAP理论,我们需要在一致性和可用性两者之间做一些妥协,值得注意的是,我们说的是“妥协”,而不是完全舍弃。从不同的侧重性上来讲,我们把系统分为三类:
- CA系统 不能分区错误容忍,当节点发生故障或者网络故障时候,系统将不能正常工作,否则不同节点的数据会发生不一致的情况,属于强一致性系统;
- CP系统 以降低可用性为代价,保持一致性和分区容忍性。当发生分区时,系统将选择大多数节点所在的分区,保持这一部分节点的一致性;同时停止小部分节点的分区再接受写入;仍然属于强一致性系统;
- AP系统 降低强一致性为代价,保持高可用和分区容忍性。当发生分区时,系统讲仍能够继续工作,多副本节点的数据在分区时会出现不一致的情况。当分区消除后,系统具有最终一致性。
系统架构师的任务,是发生分区的情况下,权衡一致性和可用性,在合理范围内最大化的实现一致性和可用性的合力,同时极力恢复分区以消除数据不一致性,并争取最好的性能。
强一致性导致的延迟
CAP描述了一致性和可用性的竞争关系,但性能(或者说延迟)是一个被遗漏的方面。
强一致性要求每一次读都能够读到最近的一次写,这就意味着,前一次的写必须反映在所有的数据副本上。如MySQL Master必须完成对所有Slave的同步,才能返回给客户端,这将大大的增加客户端的响应延迟。
幸运的是,Quorum提供了一种折中的算法,可以通过牺牲性能的方式,让系统支持强一致性,但实现最终一致性。算法要求,假设系统有N个数据副本,每一次写要同时写入W个副本,每一次读要同时读R个副本,NWR不同的组合会导致不同的一致性:
- 强一致性: W + R > N
- 最终一致性: W + R < N
强一致性举例,共3个副本,
- W写入1个副本,那么必须同时读3个副本,取最新的更新;
- W写入2个副本,那么必须同时读2个副本,取最新的更新;
- W写入3个副本,那么只需读1个副本;
Quorum的读写数可以用来作为系统读写性能的一个调节参数。W越大写越慢,但R越小读越快;反之同理。
高可用性引入的写入冲突
最终一致性让系统可以获得更好的可用性和性能。但同时也引入一些新问题,其中之一就是并行多写(Multi-Source)导致的数据冲突问题。
例如,以MySQL Master-Slave为代表的数据库架构,大部分的使用场景是,一个写入节点(Master),Master同步给多个Slave,所有同步的binlog都会在各个Slave节点上串行地顺序执行,不存在并行写入冲突。然而,在如下图多Master的场景下,Client2和Client3同时修改了Master1和Master2上的同一条数据,并且Master1想把新值Val1同步给Master2,由于Master1和Master2缺乏全局时钟,从逻辑上这两个操作是无法比较先后的,
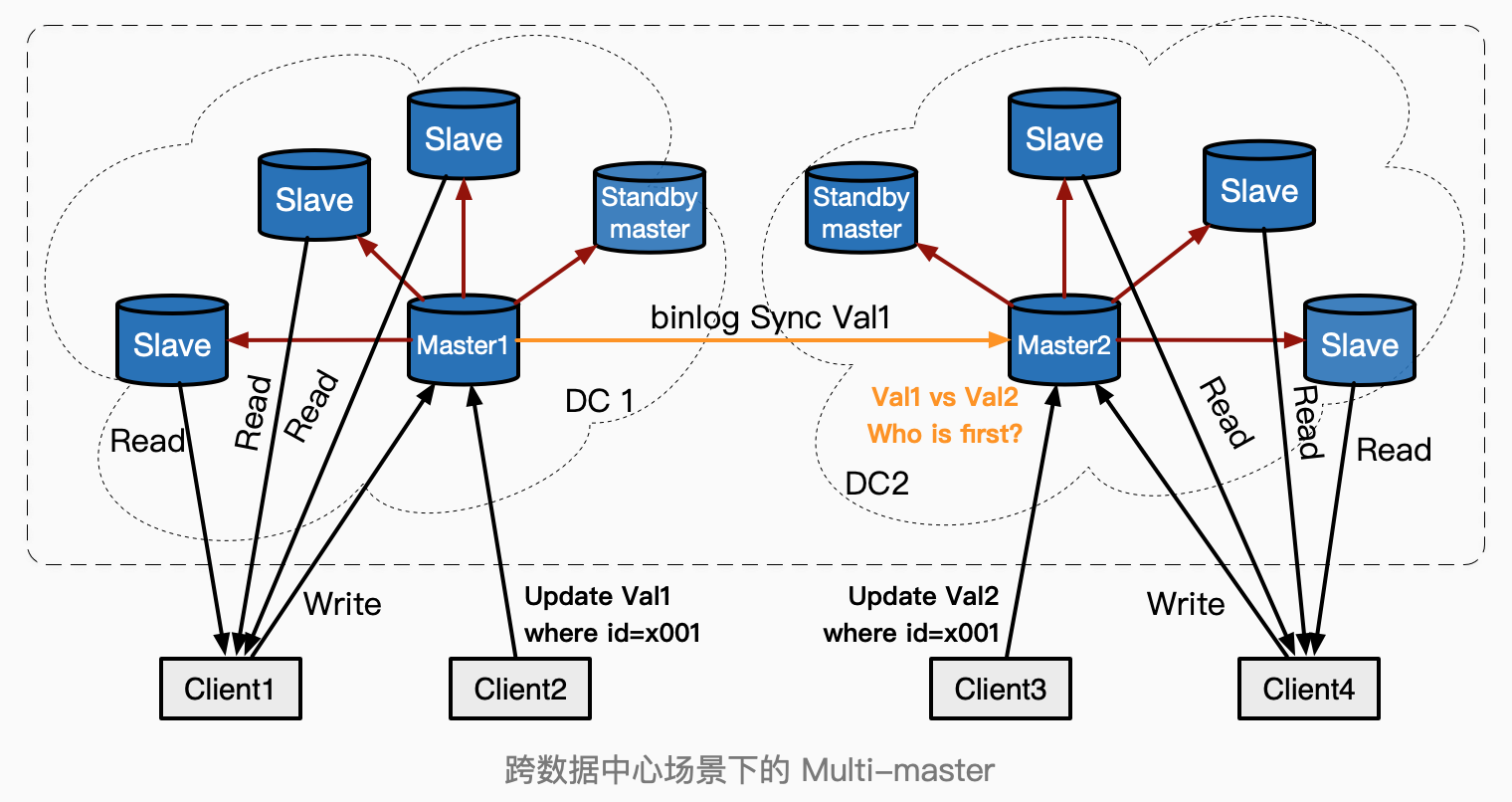
于是分布式数据库系统需要调和冲突,有几种常见的决策逻辑:
-
Last Write Wins: 给每一个操作指定一个唯一的ID(如Master服务器上的timestamp,UUID,或其他可比较的值),取较大者。
PS:需要理解的是,如使用timestamp,虽然两个Master服务器上的timestamp不具备可比性(不是全局时钟),但在遇到并行冲突时,对于系统来讲,必须选择一种决策算法(即使算法不公平),最重要的是保证一致性;对于客户端而言,最终被反馈了写入是否成功,也达到了可用性的要求;
-
固定选择某一个Master 让所有的操作都带上Master的ID,如果发现冲突,始终选择一个Master作为常胜将军(这也是上面说的的,即使不公平,但也是一种规则);
-
自定义 很多RDBMS允许自定义冲突调和策略,比如可以合并两个冲突的值,取平均值也是一种选择。
再如,为了获得更好的可用性,一些分布式系统选择了Peer-to-peer的架构,同时系统保障最终一致性。允许多个节点进行数据写入,同时每一个节点都广播(异步复制)给其他节点,这也存在并行写入冲突的可能性。
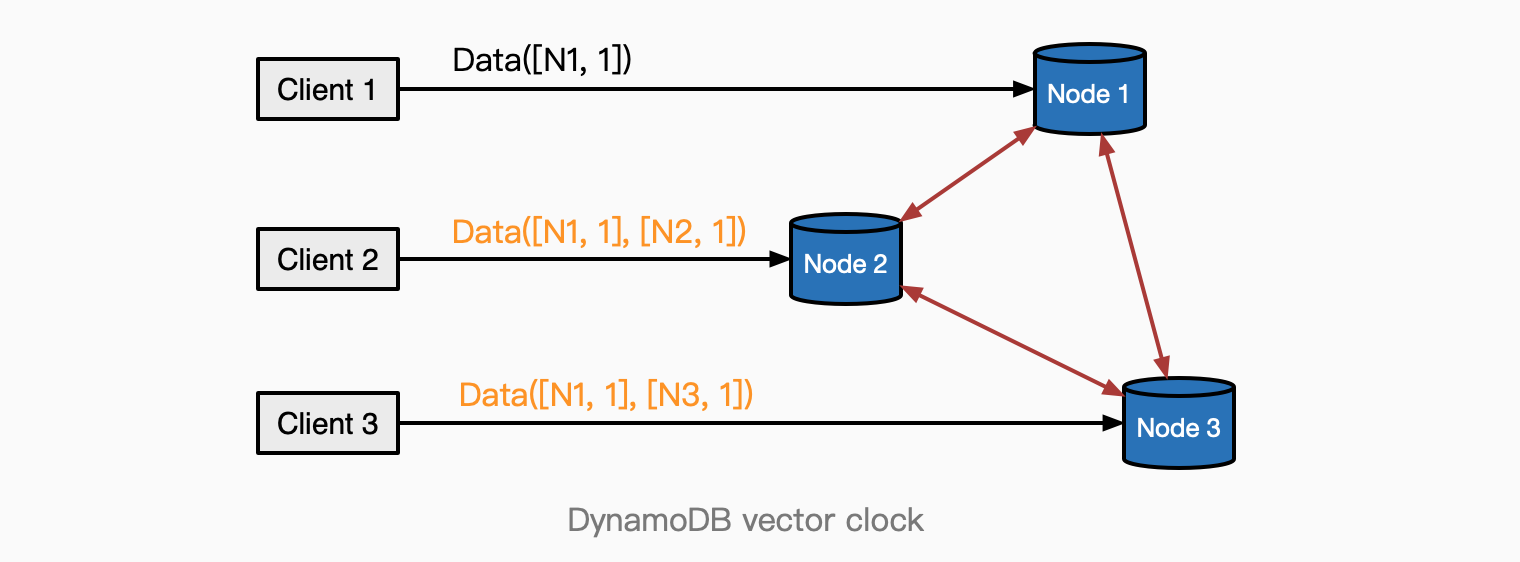
如AWS DynomoDB使用Vector Clock来检测多节点的并行写入冲突。Client2和Client3分别并行写入Node2和Node3时,通过对数据上的向量([N1,1], [N2, 1]), ([N1,1], [N3, 1])的比较,无法确定两者先后,这就检测到了冲突。于是启动冲突调和逻辑,DynamoDB也提供了类似LWW等一些自动调和算法,并支持让客户来设计调和逻辑。
多写进一步提高系统的可用性,但需要解决数据冲突,同时也使得系统设计更加复杂。
总结
分布式一致性,受到系统架构,算法,甚至客户端的交互规则的影响,是可用性、分区容忍性、及性能之间权衡的后的一种选择。
简单来讲,是多数据副本的一致性问题,它是分布式系统与用户(开发者)之间的一种协议约定,系统可以保障的一种数据一致性程度。
参考
(END)